First of all, as of today, I added new feature, called anonymization.
It is for all of the people who are afraid that their plans contain information that they don't want to (or can't) share on the internet.
It works like this:
Started with simple query:
SELECT n.nspname as "Schema", p.proname as "Name", pg_catalog.pg_get_function_result(p.oid) as "Result data type", pg_catalog.pg_get_function_arguments(p.oid) as "Argument data types", CASE WHEN p.proisagg THEN 'agg' WHEN p.proiswindow THEN 'window' WHEN p.prorettype = 'pg_catalog.trigger'::pg_catalog.regtype THEN 'trigger' ELSE 'normal' END as "Type" FROM pg_catalog.pg_proc p LEFT JOIN pg_catalog.pg_namespace n ON n.oid = p.pronamespace WHERE pg_catalog.pg_function_is_visible(p.oid) AND n.nspname <> 'pg_catalog' AND n.nspname <> 'information_schema' ORDER BY 1, 2, 4;
This generates following explain analyze:
QUERY PLAN --------------------------------------------------------------------------------------------------------------------------- Sort (cost=146.63..148.65 rows=808 width=138) (actual time=55.009..55.012 rows=71 loops=1) Sort Key: n.nspname, p.proname, (pg_get_function_arguments(p.oid)) Sort Method: quicksort Memory: 43kB -> Hash Join (cost=1.14..107.61 rows=808 width=138) (actual time=42.495..54.854 rows=71 loops=1) Hash Cond: (p.pronamespace = n.oid) -> Seq Scan on pg_proc p (cost=0.00..89.30 rows=808 width=78) (actual time=0.052..53.465 rows=2402 loops=1) Filter: pg_function_is_visible(oid) -> Hash (cost=1.09..1.09 rows=4 width=68) (actual time=0.011..0.011 rows=4 loops=1) Buckets: 1024 Batches: 1 Memory Usage: 1kB -> Seq Scan on pg_namespace n (cost=0.00..1.09 rows=4 width=68) (actual time=0.005..0.007 rows=4 loops=1) Filter: ((nspname <> 'pg_catalog'::name) AND (nspname <> 'information_schema'::name)) Total runtime: 55.117 ms (12 rows)
Simple enough. Now, when I'll put it to explain.depesz.com, I get this.
But now, on the page where I add explain, I can also mark another checkbox: “I want this plan to anonymized before saving."
After selecting this checkbox, and re-adding the same plan, I get this.
If you can't see the difference right away, open both plans in two windows/tabs, and switch between them couple of times.
Couple of important points:
- if you choose anonymization – the original version is not stored in explain.depesz.com database – i.e. it's anonymized before storing.
- within given plan the same identifier/string is always changed to the same value. I.e. if column “xxx" is present in 10 places in explain analyze, in all of the cases it will be changed to the same value – that's important to make analysis possible.
- explain.depesz.com does not store any information that would make it possible to revert anonymization, and the anonymization process is based on SHA1 hashes, so it's quite secure.
Please note also, that if you'll ask someone to help you with anonymized plans – you are responsible for translating their help to your internal, secret, column/table/function names.
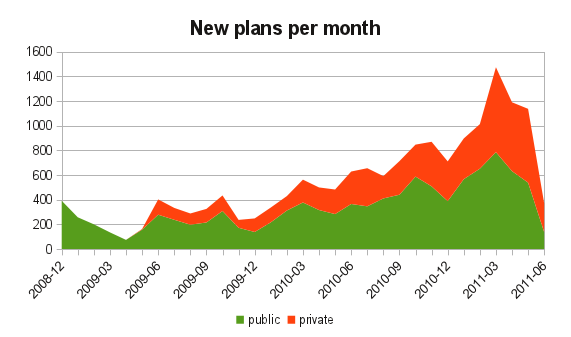
As for new stats. Since February I get over new 1000 plans monthly, and the database has now nearly 17,000 plans. It's cool to see people using the tool.
And since everybody loves graphs, here is simple graph showing new plans, per month, since the beginning: