za tydzień, w sobotę, 13 stycznia adam buraczewski wygłosi wykład nt. "słonie pracują w stadzie".
tematyka obejmie wszystkie liczące się metody klastrowania postgresa: slony, pgpool, dblink, sequoia, postgres-r i inne.
wykład odbędzie się w gliwicach – jeśli będziecie w pobliżu – polecam. temat ciekawy, a adam ma kolosalną wiedzę. i umiejętność jej przekazania.
Tag: postgresql
drzewa w sql’u – metoda “śledzenie rodzica”
jest to zdecydowanie najbardziej rozpowszechniona metoda przechowywania drzew w bazach.
zakłada ona (zgodnie z naszymy podstawowymi założeniami), że każdy element ma tylko 1 element nadrzędny (lub go nie ma – gdy jest to element główny). dzięki temu całość można zapisać w jednej tabeli
:
$ CREATE TABLE categories (
id BIGSERIAL,
parent_id INT8 REFERENCES categories (id),
codename TEXT NOT NULL DEFAULT '',
PRIMARY KEY (id)
);
CREATE UNIQUE INDEX ui_categories_picn ON categories (parent_id, codename);
nasze testowe drzewo w tej tabeli będzie wyglądało tak:
# SELECT * FROM categories; id | parent_id | codename ----+-----------+------------ 1 | [null] | sql 2 | 1 | postgresql 3 | 1 | oracle 4 | 2 | linux 5 | 3 | solaris 6 | 3 | linux 7 | 3 | windows 8 | 6 | glibc1 9 | 6 | glibc2 (9 rows)
jak widać – same podstawowe danych, jedna tabelka, mała nadmiarowość. wygląda ok. a jak to odpytać?
1. pobranie listy elementów głównych (top-levelowych)
> SELECT * FROM categories where parent_id is null;
2. pobranie elementu bezpośrednio “nad" podanym elementem
dane wejściowe:
- ID : id elementu
SELECT p.* FROM categories c JOIN categories p ON c.parent_id = p.id WHERE c.id = [ID];
jeśli zapytanie nic nie zwróci – znaczy to, że dany element był “top-levelowy".
3. pobranie listy elementów bezpośrednio “pod" podanym elementem
dane wejściowe:
- ID : id elementu
> SELECT * FROM categories WHERE parent_id = [ID];
4. pobranie listy wszystkich elementów “nad" danym elementem (wylosowanym)
dane wejściowe:
- ID : id elementu
tu pojawia się problem. można to rozwiązać selectem z dużą ilością joinów (tyle joinów ile poziomów kategorii jest powyżej naszego elementu), albo zastosować rozwiązanie algorytmiczne:
- pobierz dane dla aktualnego elementu: SELECT * FROM categories WHERE id = [ID];
- jeśli parent_id dla aktualnego elementu jest inny niż NULL wykonaj:
- SELECT * FROM categories WHERE id = [aktualny.parent_id]
- ustaw aktualny na właśnie pobrany
jest to rozwiązanie typu z wieloma zapytaniami, ale rozwiązanie z joinami ma wszystkie wady zapytań z “metody wielu tabel" (nota bene tam też można było zastosować podejście algorytmiczne, realizowane w aplikacji klienckiej)
5. pobranie listy wszystkich elementów “pod" danym elementem (wylosowanym)
dane wejściowe:
- ID : id elementu
niestety – i tym razem zapisanie tego w postaci pojedynczego zapytania będzie problematyczne. w tym przypadku należy zastosować rozwiązanie rekurencyjne:
- pobierz listę wszystkich elementów bezpośrednio pod podanym elementem (vide punkt 3)
- dla każdego z elementów powtórz powyższy punkt
- powtarzaj tak długo aż dojdziesz do sytuacji gdy już nie ma elementów poniżej.
6. sprawdzenie czy dany element jest “liściem" (czy ma pod-elementy)
dane wejściowe:
- ID : id elementu
>SELECT count(*) from categories WHERE parent_id = [ID];
jeśli zwróci 0 – to dany element jest liściem.
7. pobranie głównego elementu w tej gałęzi drzewa w której znajduje się dany (wylosowany) element
- ID : id elementu
niestety – jedyną słuszną metodą jest użycie algorytmu z punktu 4 i pobranie ostatniego elementu (takiego dla którego algorytm się kończy, bo parent_id jest NULLem.
podstawową zaletą tego rozwiązania jest to, że stała struktura tabel jest w stanie przechowywać dowolną ilość danych w drzewie – niezależnie od ilości elementów czy poziomów zagłębień.
wadami jest głównie konieczność korzystania z pewnych rozwiązań algorytmicznych zamiast użycia zapytań bazodanowych.
wyszukiwanie w/g nipu
część z was pewnie kiedyś zaprojektowała system gdzie był przechowywany numer nip.
numer nip jaki jest każdy wie – 10 cyfr, rozdzielonych myślnikami. zasadniczo – myślniki są nieważne. ale czasem ktoś (klient, urząd skarbowy, ktokolwiek) czepia się jak mu się np. nip zmieni z 522-186-96-44 na 522-18-69-644. niby ten sam. ale nie taki sam.
z tego powodu nip powinno się przechowywać w postaci takiej jak user podał.
ale – czy wyszukując nip mamy pewność, że wiemy w jakiej postaci "myślnikowej" dane są wpisane? a co jeśli mamy wpisane "522-186-96-44", a szukamy "522-18-69-644"?
czyli do wyszukiwania przydałoby się aby pamiętać bez myślników.
najprostszą wersją jest zrobienie dwóch kolumn: nip_original, nip_search. ale to jest brzydkie.
ładniej można zrobić to poprzez np. coś takiego:
mamy tabelkę:
create table test (id serial primary key, nip text not null, nazwa text not null);
i na niej zakładamy indeks w ten sposób:
create unique index test_idx on test (regexp_replace(nip, '[^0-9]', '', 'g'));
po czym sprawdzamy:
# explain analyze select * from test where regexp_replace(nip, '[^0-9]', '', 'g') = '1234567890'; QUERY PLAN ---------------------------------------------------------------------------------------------------------------- Index Scan using test_idx on test (cost=0.00..8.29 rows=1 width=54) (actual time=0.167..0.167 rows=0 loops=1) Index Cond: (regexp_replace(nip, '[^0-9]'::text, ''::text, 'g'::text) = '1234567890'::text) Total runtime: 0.261 ms (3 rows)
super.
teraz .. dobrze by było jakby dało się wyszukiwać prefixowo – aby np. w aplikacji się "podpowiadało" samo – po wpisaniu kolejnych cyfr.
aby to zrobić musimy sięgnąć po tzw. index opclass (uwaga – to jest konieczne tylko jeśli wasze locale jest inne niż C – ale pewnie jest inne):
drop index test_idx;
create unique index test_idx on test (regexp_replace(nip, '[^0-9]', '', 'g') text_pattern_ops);
no i test:
# explain analyze select * from test where regexp_replace(nip, '[^0-9]', '', 'g') like '1234%'; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Bitmap Heap Scan on test (cost=13.40..922.28 rows=500 width=54) (actual time=0.240..0.457 rows=7 loops=1) Filter: (regexp_replace(nip, '[^0-9]'::text, ''::text, 'g'::text) ~~ '1234%'::text) -> Bitmap Index Scan on test_idx (cost=0.00..13.27 rows=500 width=0) (actual time=0.162..0.162 rows=7 oops=1) Index Cond: ((regexp_replace(nip, '[^0-9]'::text, ''::text, 'g'::text) ~>=~ 1234'::text) AND (regexp_replace(nip, '[^0-9]'::text, ''::text, 'g'::text) ~<~ '1235'::text)) Total runtime: 0.593 ms (5 rows)
wow.
co prawda trzeba za każdym razem pisać tego regexp_replace'a.
czy na pewno trzeba? nie. wystarczy zrobić wrappera widokiem:
# create view test_view as select *, regexp_replace(nip, '[^0-9]', '', 'g') as search_nip from test;
i potem:
# explain analyze select * from test_view where search_nip like '123%'; QUERY PLAN ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on test (cost=13.40..923.53 rows=500 width=54) (actual time=0.375..7.384 rows=96 loops=1) Filter: (regexp_replace(nip, '[^0-9]'::text, ''::text, 'g'::text) ~~ '123%'::text) -> Bitmap Index Scan on test_idx (cost=0.00..13.27 rows=500 width=0) (actual time=0.199..0.199 rows=96 loops=1) Index Cond: ((regexp_replace(nip, '[^0-9]'::text, ''::text, 'g'::text) ~>=~ '123'::text) AND (regexp_replace(nip, '[^0-9]'::text, ''::text, 'g'::text) ~<~ '124'::text)) Total runtime: 88.251 ms
super. działa. wyszukuje niezależnie od minusów, dane trzymamy tylko raz, mamy searcha prefixowego. czego chcieć więcej?
skalowalność mysql vs. pgsql
jakiś czas temu tweakers.net robili test serwerów, gdzie niejako przy okazji porównali skalowalność mysql'a i postgresa.
panowie z mysql'a stwierdzili, że to niedobrze i wprowadzili ileśtam poprawek.
dzięki temu, tweakers.net mogli powtórzyć swoje testy – tym razem testując mysql 5.0.23-bk. efekt? oceńcie sami:
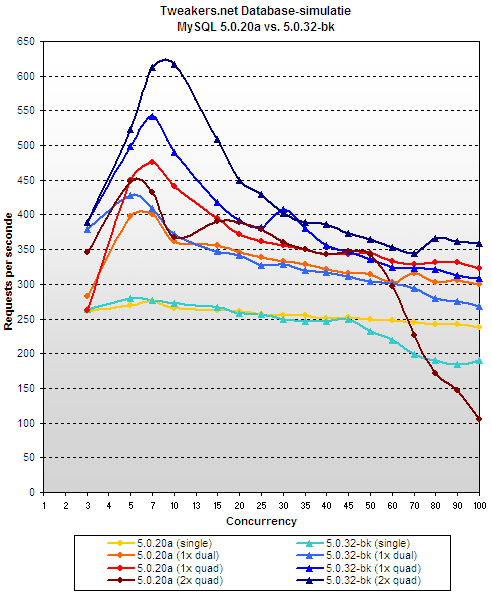
nie chciałbym wyjść na "mysql-bashing", ale jak dla mnie nadal jest cienko. wydajność w szczycie i tak jest mniejsza, a w dodatku mamy potem dramatyczny spadek. no cóż. chyba nie polubię tej bazy.
drzewa w sql’u – metoda wielu tabel
tak naprawdę to nazwa "metoda wielu tabel" nie oddaje w pełni tego o co chodzi, natomiast jest pewnym przybliżeniem.
zgodnie z tą metodą należy stworzyć dla każdego poziomu zagnieżdżenia tabelę.
w oparciu o nasze dane testowe należy stworzyć system tabel:
CREATE TABLE categories_1 (
id BIGSERIAL PRIMARY KEY,
codename TEXT NOT NULL DEFAULT ''
);
CREATE UNIQUE INDEX ui_categories_1_cn ON categories_1 (codename);
CREATE TABLE categories_2 (
id BIGSERIAL PRIMARY KEY,
parent_id INT8 NOT NULL DEFAULT 0,
codename TEXT NOT NULL DEFAULT ''
);
ALTER TABLE categories_2 ADD FOREIGN KEY (parent_id) REFERENCES categories_1 (id);
CREATE UNIQUE INDEX ui_categories_2_picn ON categories_2 (parent_id, codename);
CREATE TABLE categories_3 (
id BIGSERIAL PRIMARY KEY,
parent_id INT8 NOT NULL DEFAULT 0,
codename TEXT NOT NULL DEFAULT ''
);
ALTER TABLE categories_3 ADD FOREIGN KEY (parent_id) REFERENCES categories_2 (id);
CREATE UNIQUE INDEX ui_categories_3_picn ON categories_3 (parent_id, codename);
CREATE TABLE categories_4 (
id BIGSERIAL PRIMARY KEY,
parent_id INT8 NOT NULL DEFAULT 0,
codename TEXT NOT NULL DEFAULT ''
);
ALTER TABLE categories_4 ADD FOREIGN KEY (parent_id) REFERENCES categories_3 (id);
CREATE UNIQUE INDEX ui_categories_4_picn ON categories_4 (parent_id, codename);
i w nim dane:
# select * from categories_1;
id | codename
----+----------
1 | sql
(1 row)
# select * from categories_2;
id | parent_id | codename
----+-----------+------------
1 | 1 | oracle
2 | 1 | postgresql
(2 rows)
# select * from categories_3;
id | parent_id | codename
----+-----------+----------
1 | 2 | linux
2 | 1 | linux
3 | 1 | solaris
4 | 1 | windows
(4 rows)
# select * from categories_4;
id | parent_id | codename
----+-----------+----------
1 | 2 | glibc1
2 | 2 | glibc2
(2 rows)
jak widać pojawia się pewien problem – nieobecny w innych systemach tabel – aby prawidłowo zidentyfikować element drzewa nie wystarczy nam jego numer, ale musimy też znać poziom zagłębienia.
oczywiście możliwe jest wymuszenie nadawania numerów kolejnych tak aby nie powtarzały się w różnych tabelach, ale wtedy znalezienie który element jest w której tabeli będzie nietrywialne.
teraz pora na zadania testowe dla tego układu tabel:
1. pobranie listy elementów głównych (top-levelowych)
> SELECT * FROM categories_1;
proste i miłe.
2. pobranie elementu bezpośrednio "nad" podanym elementem
dane wejściowe:
- ID : id elementu
- X : poziom zagłębienia.
jeśli X == 1 to:
brak danych
w innym przypadku:
> SELECT p.* FROM categories_[X] c join categories_[X-1] p ON c.parent_id = p.id WHERE c.id = [ID]
pojawia się problem. zapytania są zmienne. nie jest to bardzo duży problem, ale np. utrudnia wykorzystywanie rzeczy typu "prepared statements".
3. pobranie listy elementów bezpośrednio "pod" podanym elementem
dane wejściowe:
- ID : id elementu
- X : poziom zagłębienia.
> SELECT c.* FROM categories_[X] p join categories_[X+1] c ON c.parent_id = p.id WHERE p.id = [ID]
znowu pojawia sie problem z zapytaniami o zmiennej treści (nie parametrach – treści – nazwach tabel!). dodatkowo – musimy gdzieś przechowywać informację o maksymalnym zagnieżdżeniu i sprawdzać ją przed wykonaniem zapytania – aby się nie okazało, że odwołujemy się do nieistniejącej tabeli.
4. pobranie listy wszystkich elementów "nad" danym elementem (wylosowanym)
dane wejściowe:
- ID : id elementu
- X : poziom zagłębienia.
jeśli X == 1 to:
brak danych
jeśli X == 2 to:
> SELECT c1.* FROM categories_2 c2 join categories_1 c1 ON c2.parent_id = c1.id WHERE c2.id = [ID]
jeśli X == 3 to:
> SELECT c1.*, c2.*
FROM categories_3 c3 join categories_2 c2 on c3.parent_id = c2.id join categories_1 c1 ON c2.parent_id = c1.id
WHERE c3.id = [ID]
itd.
jak widać tu problem się multiplikuje. nie tylko zmieniają nam się nazwy tabel, ale wręcz cała konstrukcja zapytania zaczyna przypominać harmonijkę – z każdym ruchem (wgłąb struktury) wyciąga się.
5. pobranie listy wszystkich elementów "pod" danym elementem (wylosowanym)
dane wejściowe:
- ID : id elementu
- X : poziom zagłębienia.
- MaxX : maksymalny poziom zagłębienia w systemie
SELECT c[X+1].* FROM categories_[X+1] c[X+1] WHERE c[X+1].parent_id = [ID]
UNION
SELECT c[X+2].*
FROM categories_[X+1] c[X+1] join categories_[X+2] c[X+2] ON c[X+1].id = c[X+2].parent_id
WHERE c[X+1].parent_id = [ID]
UNION
SELECT c[X+3].*
FROM categories_[X+1] c[X+1]
join categories_[X+2] c[X+2] ON c[X+1].id = c[X+2].parent_id
join categories_[X+3] c[X+3] ON c[X+2].id = c[X+3].parent_id
WHERE c[X+1].parent_id = [ID]
...
łaaaał. robi się coraz gorzej. napisanie tego dla np. 16 poziomów zagnieżdżenia przerasta moje chęci.
6. sprawdzenie czy dany element jest "liściem" (czy ma pod-elementy)
dane wejściowe:
- ID : id elementu
- X : poziom zagłębienia.
SELECT count(*) from categories_[X+1] WHERE parent_id = [ID]
zasadniczo proste, ale trzeba pamiętać o wcześniejszym sprawdzeniu czy przypadkiem X+1 nie jest większe od maksymalnie obsługiwanego limitu – aby uniknąć błędów w bazie.
7. pobranie głównego elementu w tej gałęzi drzewa w której znajduje się dany (wylosowany) element
dane wejściowe:
- ID : id elementu
- X : poziom zagłębienia.
jeśli X == 1 to:
> SELECT c1.* FROM categories_1 c1 WHERE id = [ID]
jeśli X == 2 to:
> SELECT c1.* FROM categories_2 c2 join categories_1 c1 ON c2.parent_id = c1.id WHERE c2.id = [ID]
jeśli X == 3 to:
> SELECT c1.*
FROM categories_3 c3 join categories_2 c2 on c3.parent_id = c2.id join categories_1 c1 ON c2.parent_id = c1.id
WHERE c3.id = [ID]
itd.
eh. chyba widzicie do czego to zmierza.
jak widać – zapisywanie tak drzew ma swoje problemy. i raczej niewiele rzeczy można w tym zrobić ładnie szybko i porządnie.
zasadniczo – nie opisywałbym tej metody gdyby nie fakt iż z nieznanych powodów jest ona bardzo często sugerowana przez ludzi których odpytuję w ramach rozmowy kwalifikacyjnej. no – a skoro się pojawia, to trzeba ją omówić. choćby pobieżnie.
drzewa w sql’u – wstęp
jakiś czas temu zainteresowała mnie metoda przechowywania wszelkiego rodzaju struktur drzewiastych w bazach danych.
dla wyjaśnienia – struktura drzewiasta jest to taki uporządkowany zbiór danych gdzie każdy element ma swój element nadrzędny, chyba, że jest elementem najwyższego rzędu.
dając przykłady z życia – drzewami są opisane wszelkiego rodzaju hierarchie – służbowe, kategorie (np. w sklepie internetowym), różnego rodzaju podziały. drzewami są też wiadomości na forach dyskusyjnych – a dokładniej – w drzewa są poukładane wątki z tych wiadomości.
ogólnie – struktury drzewiaste mają sporo zastosowań.
z tego powodu stały się one obiektem mojego zainteresowania, testów i badań. o struktury drzewiaste pytam potencjalnych pracowników na rozmowie kwalifikacyjnej.
w czasie swojej pracy z "drzewami" wyodrębniłem kilka metod które kiedyś już opisałem (link do http://www.dbf.pl/faq/tresc.html?rozdzial=1#o1_9), ale tu postaram się opisać je dokładniej i podając przy okazji wyniki pewnych testów na wydajność.
ze względu na obfitość materiału tekst ten podzielę na kilka wpisów: wstęp (to co czytacie), następnie po jednym wpisie na każdą z opisywanych metod, potem jakieś podsumowanie i na koniec kilka uwag praktycznych do wybranej przeze mnie metody.
ponieważ testowanie wydajności powinno odbywać się na sporych zestawach danych, a jednocześnie pokazywanie "o co mi chodzi" powinno być na możliwie małych ilościach – na potrzeby tego tematu przygotowałem 2 zupełnie różne zestawy danych:
1. małe drzewko w celach dydaktycznych:
to drzewko, zgodnie z konwencjami stosowanymi w tym dokumencie, ma następujące elementy:
- sql
- sql.oracle
- sql.oracle.linux
- sql.oracle.linux.glibc2
- sql.oracle.linux.glibc1
- sql.oracle.solaris
- sql.oracle.windows
- sql.postgresql
- sql.postgresql.linux
2. spory zestaw danych pobrany z katalogu dmoz – lista kategorii
dane z dmoza poddałem obróbce usuwając z nich znaki spoza zestawu A-Za-z0-9_, i ustawiając separator elementów drzewa na ".".
powstała lista elementów ma 478,870 elementów.
ścieżki z dmoz zawierają od 3 do 247 znaków, największe zagłębienie w drzewo jest w elemencie Regional.North_America.United_States.New_York.Localities.N.New_York_City.Brooklyn.Society_and_Culture.Religion.Christianity.Catholicism.Eastern_Rites.Maronite
w celu porównania wydajności różnych metod zapisu drzew będę testował następujące scenariusze testowe:
- pobranie listy elementów głównych (top-levelowych)
- pobranie elementu bezpośrednio "nad" podanym elementem
- pobranie listy elementów bezpośrednio "pod" podanym elementem
- pobranie listy wszystkich elementów "nad" danym elementem (wylosowanym)
- pobranie listy wszystkich elementów "pod" danym elementem (wylosowanym)
- sprawdzenie czy dany element jest "liściem" (czy ma pod-elementy)
- pobranie głównego elementu w tej gałęzi drzewa w której znajduje się dany (wylosowany) element
dodatkowo zostanie sprawdzona wielkość tabel i indeksów na założonej strukturze danych.
dla porównania – zapis w postaci takiej jak w pliku źródłowym zajmuje:
– tabela dmoz: 57,319,424 bajtów
– index pkey: 8,609,792 bajtów
– unikalny indeks ścieżki: 51,888,128 bajtów
tak więc – w ciągu najbliższego czasu będę pokazywał kolejne metody oraz wyniki ich testów.
dead space map
na postgresową listę patches został wysłany interesujący patch.
na razie nie wiadomo czy wejdzie do 8.3, czy może nie, na pewno nie jest jeszcze kompletny.
co robi?
panowie z ntt (taka japońska firma telekomunikacyjna) napisali obsługę dead space map. w skrócie – postgres ma przechowywać informację które ze stron danych w plikach wymagają vacuumowania, a które nie. dzięki temu nie trzeba będzie vacuumować np. całej tabeli a tylko te strony które uległy modyfikacji. ma to kolosalnie przyspieszyć vacuumowanie tabel które są spore, ale odbywa się na nich relatywnie mało update'ów i delete'ów. suuuuper! oby weszło do 8.3.
sun cluster obsługuje postgresa!
jak donosi devrim, wersja 3.2 oprogramowania sun cluster obsługuje klastrowanie postgresql'a – a przynajmniej zestawianie par active/passive przy pomocy dzielonej macierzy dyskowej. nie jest to w sumie nic ultra-przełomowego, ale dobrze wiedzieć, że sun dodaje obsługę postgresa do swoich narzędzi.
wordpress na postgresie
jak może wiecie wordpress od zawsze był na mysql'u.
dodatkowo – team wordpressa nigdy nie wykazał się chęcią modyfikacji kodu aby działał na innych platformach bazodanowych – w szczególności na postgresie. a byli pytani/proszeni przez ludzi z okolic core-teamu postgresa!
ostatnio przeczytałem na blogu drixtera, że aure zrobił nieoficjalny port wordpressa na postgresa. i to nie jakąś prehistoryczną wersję tylko 2.0.4! tak więc – zachęcam do testowania 🙂
tsearch poza contribem. w core’rze
rosyjski team (oleg i teodor) przysłał pierwszą wersję patcha przenoszącego tsearcha do podstawowego postgresa.
zmiana nie jest wielka – funkcjonalność pozostaje ta sama, ale przyjemniej się teraz konfiguruje, używa – no i nie trzeba sprawdzać czy contriby są poinstalowane 🙂
zmiany:
- tabele pg_ts_* są teraz w schemie pg_catalog. wreszcie!
- parsery, słowniki i konfiguracje są teraz częścią systemu postgresa – tak jak tabele, klasy operatorów itd. dzięki czemu są przyporządkowane do schemy – można mieć różne w różnych schemach – np. wybór różnych parserów przez autodetekcję locale – zależny od schemy!
- wybór aktualnej konfiguracji tsearcha odbywa się przez ustawienie zmiennej postgresa (czyli tak jak np. shared_buffers czy inne)
- zarządzanie konfiguracją tsearcha odbywa się teraz z użyciem poleceń sql'a (create i pochodne) a nie wyrażeń insert/update/delete. pozwala to na lepszą obsługę dumpów, tworzenia, kasowania i zarządzania zależnościami
- psql umożliwi wyświetlanie konfiguracji systemu fts poprzez polecenia \d* (\dF dokładniej)
- dodane z automatu wszystkie dostępne stemmery snowball'owe, oraz ich odpowiednie konfiguracje
- poprawki związane ze zwalnianiem pamięci
ogólnie – krok w dobrą stronę.
patch jest na razie w wersji alfa, ale myślę, że do 8.3 wejdzie na pewno.
można już się zapoznać z aktualizowaną na bieżąco dokumentacją – na razie na stronach olega i teodora, ale już niedługo w standardowych doc'ach postgresa.
aha. informacyjnie – prace nad wdrożeniem tsearcha do core'a są sponsorowane przez enterprisedb – producenta wersji postgresql'a zmodyfikowanej w celu zachowania wiekszej kompatybilnosci z oracle'em.