to akurat poprawka malutka, ale jak dla mnie po prostu bogosławiona.
jak może wiecie polecenie update (a także delete) może aktualizować dane z pomocą innej tabeli. przykładowo:
# CREATE TABLE statusy (id serial PRIMARY KEY, kod TEXT); NOTICE: CREATE TABLE will create implicit sequence "statusy_id_seq" for serial column "statusy.id" NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "statusy_pkey" for table "statusy" CREATE TABLE # INSERT INTO statusy (kod) VALUES ('new'), ('open'), ('resolved'), ('rejected'); INSERT 0 4 # CREATE TABLE zgloszenia (id serial, temat TEXT, status_id int NOT NULL references statusy (id)); NOTICE: CREATE TABLE will create implicit sequence "zgloszenia_id_seq" for serial column "zgloszenia.id" NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "zgloszenia_pkey" for table "zgloszenia" CREATE TABLE # INSERT INTO zgloszenia (temat, status_id) VALUES ('a', 1), ('b', 2), ('c', 3), ('d', 4); INSERT 0 4 # ALTER TABLE zgloszenia add column status TEXT; ALTER TABLE # UPDATE zgloszenia SET status = s.kod FROM statusy s WHERE s.id = status_id; UPDATE 4 # SELECT * FROM zgloszenia;
| id | temat | status_id | status |
|---|
(4 rows)
fajne. ale – jeśli nazwy kolumn się powtarzają (np. ja mam w każdej tabeli pole “id" będące primary key'em) to trzeba postgresowi powiedzieć o które pole dokładnie mi chodzi. póki używam id z tabel dołączanych to nie problem – w “FROM" mogę podać alias na tabelę (w przykładzie powyżej: “s"). ale już tabeli którą aktualizuję – nie mogłem aliasować.
teraz już mogę. dzięki czemu nawet przy aktualizowaniu tabeli o długiej nazwie i używaniu w warunkach jej pól nie będę miał kosmicznie długiego sql'a – trudnego do czytania i poprawiania.
wygląda to na przykład tak:
UPDATE wynagrodzenia_pracownikow s SET pensje = sum(p.wynagrodzenie) FROM wynagrodzenia_pracownikow p WHERE p.przelozony_id = s.id;
ten sam mechanizm działa w przypadku delete'ów join-ujących tabele w celu stworzenia odpowiednich warunków.
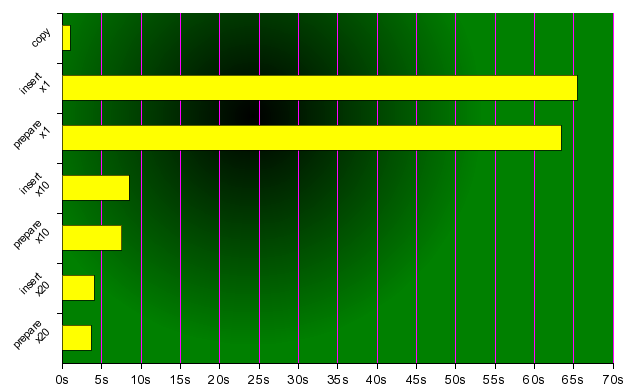 jak widac przyspieszenie insertów jest znaczne. czy to wszystko? nie!
jak widac przyspieszenie insertów jest znaczne. czy to wszystko? nie!
