jakiś czas temu tweakers.net robili test serwerów, gdzie niejako przy okazji porównali skalowalność mysql'a i postgresa.
panowie z mysql'a stwierdzili, że to niedobrze i wprowadzili ileśtam poprawek.
dzięki temu, tweakers.net mogli powtórzyć swoje testy – tym razem testując mysql 5.0.23-bk. efekt? oceńcie sami:
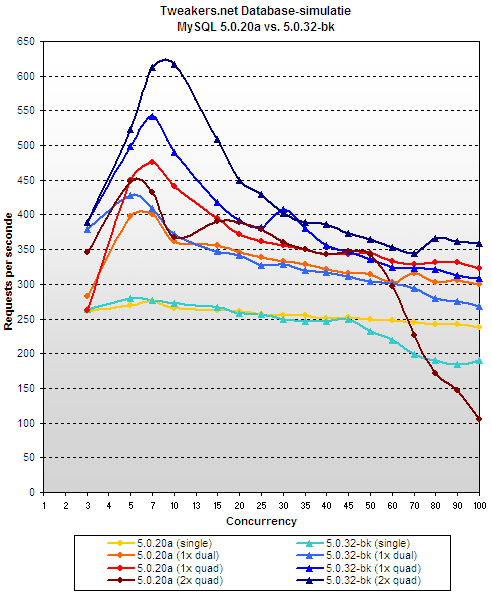
nie chciałbym wyjść na "mysql-bashing", ale jak dla mnie nadal jest cienko. wydajność w szczycie i tak jest mniejsza, a w dodatku mamy potem dramatyczny spadek. no cóż. chyba nie polubię tej bazy.
Author: depesz
tapeta na dziś

tapeta na dziś

deviantart
indiana jones i świątynia mamony
w ostatni piątek, 29 grudnia 2006, george lucas obwieścił, że w 2007 roku rozpocznie się kręcenie 4 części przygód indiany jones'a. film ma być dziełem tej samej "trójcy": lucasa, spielberga i forda.
<sarkazm>"nie mogę się doczekać"</sarkazm>
ujmę to tak – jest paru aktorów którzy wkurzają mnie bardziej niż ford. ale żaden nie był nigdy tak wysoko by potem spaść tak nisko. człowiek którego wielbiły tłumy (no, ja do tych tłumów nie należałem, bo jedyne role jego jakie faktycznie lubię to indy) spadł do poziomu "6 dni i 7 nocy"?
myślałem, że to będzie dno.
potem był firewall.
a teraz to – ponad 60 letni aktor będzie grał w filmie stricte przygodowym? jezu. to ja już wolę larę croft. przynajmniej patrząc na nią nie mam odruchów wymiotnych.
choroba szalonych krów – przeszłością?
z pewnym zaskoczeniem przeczytałem o tym, że naukowcy w stanach przeprowadzili mutację krów w sposób który ma (finalne wyniki testów za około 2 lata) uodpornić ją na bse – chorobę szalonych krów.
co to dla nas oznacza? z jednej strony widać, że coraz pewniej się czujemy manipulując w genach. z drugiej strony – jeśli ta "terapia" okaże się być bezpieczna, a potem jeśli mięso z takich krów zostanie zaakceptowane do dystrybucji i spożycia – zniknie ryzyko, że zachorujemy na chorobę Creutzfeldta-Jakoba.
czy to dobrze? na pierwszy rzut oka – oczywiście tak.
na drugi – modyfikacje przy genach są niebezpieczne – nie znamy całego spektrum "zastosowań" każdego z genów. a modyfikowanie ich w celu osiągnięcia konkretnych korzyści przypomina naprawianie reaktora atomowego młotkiem.
natomiast tym co mnie osobiście nastraja najgorzej jest zupełnie co innego.
załóżmy, że modyfikacja genów faktycznie uodparnia na bse.
i że mięso zostaje dopuszczone do handlu.
i że ludzie zaczynają je kupować.
jedzą. wszystko jest ok.
i co się dzieje? wchodzi do gry stary czynnik: ekonomia, zwana także pod nazwą pazerność.
skoro mogę teraz bezkarnie dawać krowom to od czego wcześniej chorowały, to czemu by nie? to może jeszcze coś do tego dorzucić? wołowina jest smaczna, ludzie chcą ją kupować bo jest zdrowa i bezpieczna, więc trzeba obniżyć koszty. za jaki czas pojawi się kolejne bse?
nowe opony
armia amerykańska rocznie zużywa około 200,000 sztuk opon do humvee – wojskowego pierwowzoru hummerów.
humvee są świetnie opancerzone, ale na kołach nadal mają prawie zwykłe opony. prawie zwykłe – przeżyją przestrzelenie i jazdę bez powietrza. ale nie za długą i nie za szybko. a i przestrzelina powinna być raczej mała.
a to jest już poważany problem – w czasie misji typu irak, afganistan czy cokolwiek tego typu różnica między mobilnością a jej brakiem to także różnica miedzy życiem a śmiercią.
rozwiązanie wymyśliła pewna mała firma z wisconsin.
wymyślili mianowicie koło bez zamkniętej, pompowanej przestrzeni:

tego typu opony już były. to co wyróżnią tę to fakt, że podobno uporano się z wszystkimi problemami z tego typu sprzętem. co z tego wyjdzie? zobaczymy. ja jestem pełen optymizmu – jeśli w tym roku miałoby to wejść do wojska, to za jakieś 2-3 pojawiłoby się w samochodach cywilnych. a to może oznaczać, że szybciej pojawi się rozwiązanie problemu dziur w drogach niż nasze ekipy rządzące te dziury usuną.
międzynarodowa współpraca
w 2005 roku francja i niemcy podpisały międzynarodowe porozumienie w ramach którego miała być stworzona nowa wyszukiwarka internetowa.
do tego "sojuszu" przystąpiły też bertelsman oraz france i deutche telecomy.
prawda, że pięknie?
osobiście myślałem, że padnę ze śmiechu jak gdzieś wyczytałem, że projekt będzie miał budżet 300 milionów dolarów. na tyle się państwa członkowskie dogadały. w skrócie – od początku widać, że jest to żart a nie prawdziwe zagrożenie dla google'a.
no i stało się. jak się okazuje niemcy stwierdzili, że dogadanie się z francuzami jest nierealne i wycofują się w projektu. stworzą własną wyszukiwarkę. a francuzi będą kontynuować budowanie swojej. prawda, że piękne?
na ile oceniacie szanse, że którykolwiek z tych teamów zrobi coś co będzie w stanie konkurować choćby z ask.com, nie mówiąc już o google'u? 0.1% 0.01%?
meta-poprawka
najczęstsza przyczyną problemów z bezpieczeństwem są błędy w zarządzaniu pamięcią – znane grupowo pod nazwą buffer overflowów. poza nimi jest kilka innych typów błędów które co prawda nie tworzą zagrożeń bezpieczeństwa systemu, ale np. po wodują krytyczne wyjścia albo zawieszenia z aplikacji.
błędy te mają różną postać, ale w większości sprowadzają się do mniej więcej tego samego.
zauważyli to badacze z uniwersytetu w amherst, którzy następnie wraz z programistami z intela i microsoftu stworzyli interesujące narzędzie: diehard.
diehard jest biblioteką której załadowanie przed uruchomieniem programu zabezpiecza przed większością standardowych problemów w obsłudze pamięci.
diehard nie zapewnia bezpieczeństwa – on po prostu powoduje, że pewne błędy są lepiej obsługiwane – w sposób nie zagrażający ani bezpieczeństwu ani stabilności.
biblioteka ta jest napisana tak by działała zarówno na windows jak i linuksie (są też źródła, więc da się odpalić na innych systemach). z tym, że na windowsach potrafi jak na razie zabezpieczać tylko jedną aplikację – firefoxa. na linuksie może zabezpieczać dowolny soft.
rozszerzanie funkcjonalności serwisów webowych
pewnie spora część was – moich czytelników – wie co to apache i nie raz stawiała serwisy pod nim. a ilu/ile z was zna i korzysta z mod_rewrite?
mod_rewrite jest najwspanialszym modułem jaki kiedykolwiek powstał dla apache'a. i najgorszym koszmarem.
w dokumentacji do tego modułu można znaleźć dwa motta:
"The great thing about mod_rewrite is it gives you all the configurability and flexibility of Sendmail. The downside to mod_rewrite is that it gives you all the configurability and flexibility of Sendmail."
to jest zabawne, ale tylko dla ludzi znających sendmaila.
drugie motto jest zdecydowanie prostsze w odbiorze:
"Despite the tons of examples and docs, mod_rewrite is voodoo. Damned cool voodoo, but still voodoo."
czy jednak tak faktycznie jest? czy jest to niemożliwe do opanowania?
dziś chciałbym pokazać dwa proste przykłady użycia mod_rewrite.
jest sobie taki program – request tracker. służy on rejestracji i obsługi wszelkiego rodzaju "zgłoszeń". zgłoszenia są numerowane, a dodatkowo każde zgłoszenie jest w określonej "kolejce" – czymś jakby katalogu/kategorii.
system działa nawet fajnie (z dokładnością do wydajności, ale o tym już pisałem). natomiast brakuje mi kilku prostych rzeczy. dokładniej – możliwości podania prostego w urlu, że chcę zobaczyć zgłoszenie numer XXX, czy dane z kolejki YYY.
o ile zgłoszenie numer XXX ma jeszcze prostego urla:
http://rt.domena/Ticket/Display.html?id=XXX
o tyle url do obejrzenia kolejki jest "wygięty", gdyż działa z użyciem mechanizmu search'a, więc wygląda tragicznie:
http://rt.domena/Search/Results.html?Query=Queue%20=%20'YYY'%20AND%20(Status%20=%20'open'%20OR%20Status%20=%20'new')&Rows=50
wkurzające. i niemożliwe do wpisania "z palca".
tak więc stwierdziłem, że dobuduję sobie obsługę odpowiednich urli. ideałem byłoby dorobienie tego bez modyfikowania kodu – aby nie musieć back-portować poprawek po każdy upgrade'dzie.
tak więc, do definicji wirtuala rt.domena dopisałem te 3 linijki:
RewriteEngine on
RewriteRule ^/([0-9]+)$ /Ticket/Display.html?id=$1 [R,L]
RewriteRule ^/([A-Za-z0-9-]+)$ /Search/Results.html?Query=Queue\%20=\%20'$1'\%20AND\%20(Status\%20=\%20'open'\%20OR\%20Status\%20=\%20'new')&Rows=50 [NE,R,L]
co one robią?
pierwsza linijka – po prostu włącza silnik rewrite'ów.
druga – każdy url zaczynający pasujący do regexpa ^/([0-9]+)$ (czyli każdy typu: http://rt.domena/123, gdzie zamiast 123 może być dowolna liczba) zamienia na http://rt.domena/Ticket/Display.html?id=123
oczywiście numer ticketu (123) jest przepisywany.
flagi na końcu – [R,L] oznaczają odpowiednio, że (R) wynikiem rewrite'a ma być redirect (http/302), oraz (L), że przetwarzanie reguł ma się zakończyć na tej – o ile zostanie dopasowana.
druga linijka dopasowuje się do wszystkich urli takich jak: http://rt.domena/COSTAM
gdzie COSTAM jest ciągiem znaków składającym się z dużych i małych liter oraz cyfr.
tym razem do flag dodałem dodatkowo "NE". ‘NE' oznacza, że url ma zostać przesłany do przeglądarki bez dalszej obróbki url'i (escape'owania przy pomocy url-encodingu).
i to wszystko.
dzięki temu teraz mogę używać urli:
http://rt.domena/NUMER_TICKETU
http://rt.domena/NAZWA_KOLEJKI
i działają one zgodnie z przewidywaniami 🙂
tak więc – polecam przyjrzenie się mod_rewrite'owi. pozwala on w trywialny sposób dodać nowe funkcjonalności do istniejących serwisów. i popsuć wszystko w sposób który będzie się wydawał całkowicie magiczny. no cóż – jak voodoo, to voodoo.
mimo tego – polecam poznanie tego modułu. osobiście ratował mi odwłok przynajmniej kilkanaście razy.
drzewa w sql’u – metoda wielu tabel
tak naprawdę to nazwa "metoda wielu tabel" nie oddaje w pełni tego o co chodzi, natomiast jest pewnym przybliżeniem.
zgodnie z tą metodą należy stworzyć dla każdego poziomu zagnieżdżenia tabelę.
w oparciu o nasze dane testowe należy stworzyć system tabel:
CREATE TABLE categories_1 (
id BIGSERIAL PRIMARY KEY,
codename TEXT NOT NULL DEFAULT ''
);
CREATE UNIQUE INDEX ui_categories_1_cn ON categories_1 (codename);
CREATE TABLE categories_2 (
id BIGSERIAL PRIMARY KEY,
parent_id INT8 NOT NULL DEFAULT 0,
codename TEXT NOT NULL DEFAULT ''
);
ALTER TABLE categories_2 ADD FOREIGN KEY (parent_id) REFERENCES categories_1 (id);
CREATE UNIQUE INDEX ui_categories_2_picn ON categories_2 (parent_id, codename);
CREATE TABLE categories_3 (
id BIGSERIAL PRIMARY KEY,
parent_id INT8 NOT NULL DEFAULT 0,
codename TEXT NOT NULL DEFAULT ''
);
ALTER TABLE categories_3 ADD FOREIGN KEY (parent_id) REFERENCES categories_2 (id);
CREATE UNIQUE INDEX ui_categories_3_picn ON categories_3 (parent_id, codename);
CREATE TABLE categories_4 (
id BIGSERIAL PRIMARY KEY,
parent_id INT8 NOT NULL DEFAULT 0,
codename TEXT NOT NULL DEFAULT ''
);
ALTER TABLE categories_4 ADD FOREIGN KEY (parent_id) REFERENCES categories_3 (id);
CREATE UNIQUE INDEX ui_categories_4_picn ON categories_4 (parent_id, codename);
i w nim dane:
# select * from categories_1;
id | codename
----+----------
1 | sql
(1 row)
# select * from categories_2;
id | parent_id | codename
----+-----------+------------
1 | 1 | oracle
2 | 1 | postgresql
(2 rows)
# select * from categories_3;
id | parent_id | codename
----+-----------+----------
1 | 2 | linux
2 | 1 | linux
3 | 1 | solaris
4 | 1 | windows
(4 rows)
# select * from categories_4;
id | parent_id | codename
----+-----------+----------
1 | 2 | glibc1
2 | 2 | glibc2
(2 rows)
jak widać pojawia się pewien problem – nieobecny w innych systemach tabel – aby prawidłowo zidentyfikować element drzewa nie wystarczy nam jego numer, ale musimy też znać poziom zagłębienia.
oczywiście możliwe jest wymuszenie nadawania numerów kolejnych tak aby nie powtarzały się w różnych tabelach, ale wtedy znalezienie który element jest w której tabeli będzie nietrywialne.
teraz pora na zadania testowe dla tego układu tabel:
1. pobranie listy elementów głównych (top-levelowych)
> SELECT * FROM categories_1;
proste i miłe.
2. pobranie elementu bezpośrednio "nad" podanym elementem
dane wejściowe:
- ID : id elementu
- X : poziom zagłębienia.
jeśli X == 1 to:
brak danych
w innym przypadku:
> SELECT p.* FROM categories_[X] c join categories_[X-1] p ON c.parent_id = p.id WHERE c.id = [ID]
pojawia się problem. zapytania są zmienne. nie jest to bardzo duży problem, ale np. utrudnia wykorzystywanie rzeczy typu "prepared statements".
3. pobranie listy elementów bezpośrednio "pod" podanym elementem
dane wejściowe:
- ID : id elementu
- X : poziom zagłębienia.
> SELECT c.* FROM categories_[X] p join categories_[X+1] c ON c.parent_id = p.id WHERE p.id = [ID]
znowu pojawia sie problem z zapytaniami o zmiennej treści (nie parametrach – treści – nazwach tabel!). dodatkowo – musimy gdzieś przechowywać informację o maksymalnym zagnieżdżeniu i sprawdzać ją przed wykonaniem zapytania – aby się nie okazało, że odwołujemy się do nieistniejącej tabeli.
4. pobranie listy wszystkich elementów "nad" danym elementem (wylosowanym)
dane wejściowe:
- ID : id elementu
- X : poziom zagłębienia.
jeśli X == 1 to:
brak danych
jeśli X == 2 to:
> SELECT c1.* FROM categories_2 c2 join categories_1 c1 ON c2.parent_id = c1.id WHERE c2.id = [ID]
jeśli X == 3 to:
> SELECT c1.*, c2.*
FROM categories_3 c3 join categories_2 c2 on c3.parent_id = c2.id join categories_1 c1 ON c2.parent_id = c1.id
WHERE c3.id = [ID]
itd.
jak widać tu problem się multiplikuje. nie tylko zmieniają nam się nazwy tabel, ale wręcz cała konstrukcja zapytania zaczyna przypominać harmonijkę – z każdym ruchem (wgłąb struktury) wyciąga się.
5. pobranie listy wszystkich elementów "pod" danym elementem (wylosowanym)
dane wejściowe:
- ID : id elementu
- X : poziom zagłębienia.
- MaxX : maksymalny poziom zagłębienia w systemie
SELECT c[X+1].* FROM categories_[X+1] c[X+1] WHERE c[X+1].parent_id = [ID]
UNION
SELECT c[X+2].*
FROM categories_[X+1] c[X+1] join categories_[X+2] c[X+2] ON c[X+1].id = c[X+2].parent_id
WHERE c[X+1].parent_id = [ID]
UNION
SELECT c[X+3].*
FROM categories_[X+1] c[X+1]
join categories_[X+2] c[X+2] ON c[X+1].id = c[X+2].parent_id
join categories_[X+3] c[X+3] ON c[X+2].id = c[X+3].parent_id
WHERE c[X+1].parent_id = [ID]
...
łaaaał. robi się coraz gorzej. napisanie tego dla np. 16 poziomów zagnieżdżenia przerasta moje chęci.
6. sprawdzenie czy dany element jest "liściem" (czy ma pod-elementy)
dane wejściowe:
- ID : id elementu
- X : poziom zagłębienia.
SELECT count(*) from categories_[X+1] WHERE parent_id = [ID]
zasadniczo proste, ale trzeba pamiętać o wcześniejszym sprawdzeniu czy przypadkiem X+1 nie jest większe od maksymalnie obsługiwanego limitu – aby uniknąć błędów w bazie.
7. pobranie głównego elementu w tej gałęzi drzewa w której znajduje się dany (wylosowany) element
dane wejściowe:
- ID : id elementu
- X : poziom zagłębienia.
jeśli X == 1 to:
> SELECT c1.* FROM categories_1 c1 WHERE id = [ID]
jeśli X == 2 to:
> SELECT c1.* FROM categories_2 c2 join categories_1 c1 ON c2.parent_id = c1.id WHERE c2.id = [ID]
jeśli X == 3 to:
> SELECT c1.*
FROM categories_3 c3 join categories_2 c2 on c3.parent_id = c2.id join categories_1 c1 ON c2.parent_id = c1.id
WHERE c3.id = [ID]
itd.
eh. chyba widzicie do czego to zmierza.
jak widać – zapisywanie tak drzew ma swoje problemy. i raczej niewiele rzeczy można w tym zrobić ładnie szybko i porządnie.
zasadniczo – nie opisywałbym tej metody gdyby nie fakt iż z nieznanych powodów jest ona bardzo często sugerowana przez ludzi których odpytuję w ramach rozmowy kwalifikacyjnej. no – a skoro się pojawia, to trzeba ją omówić. choćby pobieżnie.