Some time ago I wrote about getting fast pagination. While fast, it had some problems which made it unusable for some. Specifically – you couldn't get page count, and easily jump to page number N.
I did some thinking on the subject, and I think I found a way to make it all work. Quite fast. And with not big overhead. Let me show you.
Before I will continue, let me put emphasis on one, very simple, but important thing:
Following post is just example of implementation of an idea. There is no warranty nor even suggestion that it will work well for any case other than the example itself. If you want to use it in your environment – you're free to do so, but you are the one responsible for it, not me.
To make the examples of code really work, I created simple test table:
$ \d test
Table "public.test"
Column | Type | Modifiers
--------+---------+---------------------------------------------------
id | integer | not null default nextval('test_id_seq'::regclass)
title | text |
Indexes:
"test_pkey" PRIMARY KEY, btree (id)
"idx_title" btree (title)As for data in there – these are titles of items sold on Etsy, which I got permission to use in my example. These look like this:
$ select title from test limit 5; title ------------------------------------------------- Make Your Own Cushion Log Cabin Patchwork Cover Love in a Mist - Notecard Make Your Own Log Cabin Patchwork Cushion Kit Crochet Pattern SEXY BEADED THONG SANDALS Beauty Botanical Perfume Oil .5 ounces (5 rows)
Some statistics, so you'll see how large is the dataset:
$ select count(*), min(length(title)), avg(length(title)), max(length(title)), sum(length(title)), pg_size_pretty(pg_table_size('test')), pg_size_pretty(pg_indexes_size('test')) from test; -[ RECORD 1 ]--+-------------------- count | 63748218 min | 0 avg | 48.3373979802855038 max | 374 sum | 3081422984 pg_size_pretty | 5197 MB pg_size_pretty | 5861 MB
It has been loaded to fresh 9.1beta1 database, on SSD disk.
Normal approach to getting pagination is: get count of elements, divide by elements per page, and then use order by with limit and offset to get items for given page.
So, the count looks like:
$ explain analyze select count(*) from test; QUERY PLAN --------------------------------------------------------------------------------------------------------------------------- Aggregate (cost=1461831.70..1461831.71 rows=1 width=0) (actual time=10172.588..10172.589 rows=1 loops=1) -> Seq Scan on test (cost=0.00..1302461.16 rows=63748216 width=0) (actual time=0.004..5745.134 rows=63748218 loops=1) Total runtime: 10172.617 ms (3 rows)
Getting 2nd page of results, where page is 25 elements would be:
$ explain analyze select * from test order by title asc limit 25 offset 25; QUERY PLAN --------------------------------------------------------------------------------------------------------------------------------------- Limit (cost=99.95..199.90 rows=25 width=53) (actual time=0.035..0.060 rows=25 loops=1) -> Index Scan using idx_title on test (cost=0.00..254869320.41 rows=63748216 width=53) (actual time=0.014..0.052 rows=50 loops=1) Total runtime: 0.078 ms (3 rows)
This is all good, but let's see how the time changes when asking for pages that are later on. To do so, I wrote simple bash script:
#!/bin/bash for i in {0..100} do page=$(( i * 50 + 1 )) offset=$(( page * 25 - 25 )) printf '\\echo Page: %d\n' $page printf '\\o /dev/null\n' printf 'select * from test order by title asc limit 25 offset %d;\n' $offset printf '\\o | grep Limit\n' printf 'explain analyze select * from test order by title asc limit 25 offset %d;\n' $offset printf '\\o' done
Which generates sql (psql actually) script, which looks like this:
\echo Page: 1 \o /dev/null select * from test order by title asc limit 25 offset 0; \o | grep Limit explain analyze select * from test order by title asc limit 25 offset 0; \o\echo Page: 51 \o /dev/null select * from test order by title asc limit 25 offset 1250; \o | grep Limit explain analyze select * from test order by title asc limit 25 offset 1250;
And so on.
Result of running it via psql looks like this:
Page: 1 Limit (cost=0.00..99.95 rows=25 width=53) (actual time=0.009..0.030 rows=25 loops=1) Page: 101 Limit (cost=9995.16..10095.11 rows=25 width=53) (actual time=2.617..2.639 rows=25 loops=1) Page: 201 Limit (cost=19990.31..20090.26 rows=25 width=53) (actual time=3.843..3.861 rows=25 loops=1)
And from there I can draw a nice (well, kind-of nice) chart:
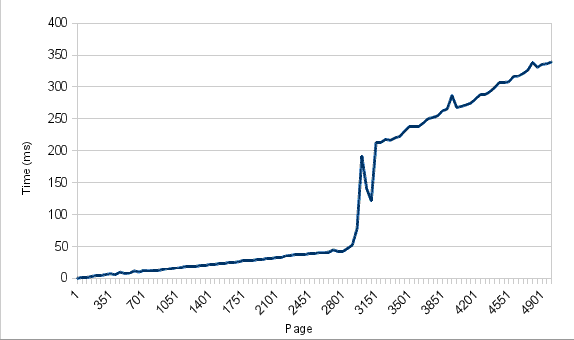
The bump ~ page 3000 is apparently not related to plan change, but some other things:
Page: 2901 Limit (cost=289859.50..289959.45 rows=25 width=53) (actual time=48.044..48.063 rows=25 loops=1) -> Index Scan using idx_title on test (cost=0.00..254869320.41 rows=63748216 width=53) (actual time=0.009..45.086 rows=72525 loops=1) Total runtime: 48.081 ms Page: 2951 Limit (cost=294857.07..294957.02 rows=25 width=53) (actual time=76.772..76.790 rows=25 loops=1) -> Index Scan using idx_title on test (cost=0.00..254869320.41 rows=63748216 width=53) (actual time=0.009..73.715 rows=73775 loops=1) Total runtime: 76.807 ms Page: 3001 Limit (cost=299854.65..299954.60 rows=25 width=53) (actual time=172.577..172.655 rows=25 loops=1) -> Index Scan using idx_title on test (cost=0.00..254869320.41 rows=63748216 width=53) (actual time=0.028..169.002 rows=75025 loops=1) Total runtime: 172.675 ms Page: 3051 Limit (cost=304852.23..304952.18 rows=25 width=53) (actual time=144.738..144.756 rows=25 loops=1) -> Index Scan using idx_title on test (cost=0.00..254869320.41 rows=63748216 width=53) (actual time=0.010..141.088 rows=76275 loops=1) Total runtime: 144.774 ms
As you can see index scans are used all the time, but after some time the actual time spikes pretty significantly.
Of course the simplest approach is not to allow users to go past some page. This is very common situation – even Google limits number of pages you can view. But what if you don't want to. Or cannot?
First, let me explain the general idea. Let's imagine you have following items:
a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z,...
That is – all letters, in order.
You can easily get to specific letter. But if you want to get Nth letter, you have to scan from some known location.
So, to get to 3rd letter, you have to find first element, and then move twice to next page.
Similarly to get to 5th letter you have to issue 5 “movements": go to first and then four times “move next".
Now. Let's assume that we will memorize positions of some items. For example we will memorize that 10th object is “j", and 20th is “t".
With this information, it lets us use interesting shortcut. For example – when searching for 11th object, we don't have to find first, and move 10 times “next", but instead we can get to 10th (memorized “j"), and move “next" only once.
What's more. This also works “backward". If I'd want 9th object – previously I'd have to: find next, move next 8 times, but now I can: go to 10th, move “previous" once.
So, if we could somehow memorize positions of some well-placed dividers, we could simplify paging a lot.
Dividers basically split into ranges, so if we'd “split" the whole table into ranges of more or less the same, relatively small, size – it could be pretty useful.
First idea on splitting was to use first letter of title. Checked the counts, and it looks like this:
$ select substr(lower(title), 1, 1), count(*) from test group by 1 order by 1; substr | count --------+--------- | 1 | 604 : | 21 $ | 30 * | 1 & | 11 0 | 31053 1 | 2110746 2 | 1213456 3 | 524973 4 | 541891 5 | 628592 6 | 480335 7 | 125257 8 | 281007 9 | 88280 a | 2646571 á | 2 à | 5 ä | 7 b | 4695762 c | 5456577 ç | 4 d | 1743950 e | 1095043 é | 22 f | 2714546 g | 2031675 h | 2512568 i | 837045 î | 1 j | 653526 k | 659074 l | 2682391 m | 2714875 n | 1364448 o | 1464460 ô | 1 ö | 3 p | 4052944 q | 120908 r | 3714226 s | 7097155 t | 3004895 u | 349433 ü | 7 v | 3956609 w | 1572128 x | 47647 y | 385276 z | 148176 (51 rows)
Not really good. Some ranges would be very small, and the other would be way too big. How do I know that they are too big? It's simple – maximal size should be chosen in such way that it's half (because we can scan both forward and backward) would still guarantee fast results.
In my case, it seems that offset 50,000 took around 30ms, which is pretty acceptable for me, so the range should be ~ 100,000 rows.
So, let's see how it would look – whole range of titles divided into 100,000k rows:
create table just_index as select title from ( select title, ( row_number() over (order by title) ) % 100000 as div from test order by title ) x where div = 0;
Result of this, is too big to show in here (it's 637 rows), but the first 10 rows are:
$ select * from just_index order by title asc limit 10; title -------------------------------------------------------------------------------------------------------------------------------------------- 100 Dollars Ceramics Gift Certificate 100pcs light yellow and bule flowers D1.5cm 100% wool shrug for Tonner, Cami, or Ellowyne 10 Feet Silver Mother-Son Chains CHSM020Y-S 10% OFF SALE VTG SOLID BRONZE RARE TRINITARIAN MEDAL CROSS CRUCIFIX FOR ROSARY RELIGIOUS JEWELRY CROSS PENDANT NECKLACE 10pcs Grey Transparent Glass Leafs M-GLF001a 10 Small BLACK Glue on Bails . . . XO Bails. . . LEAD FREE. . . Use these with your Bottle Caps Wood Polymer Clay Glass and Scrabble Tiles 11in Flannel Flared Cloth Menstrual Pad - 70s Wallpaper w/ Mottled Brown 12 Fortune Teller Fish Novelty Favors 12pcs 50mm ANTIQUE BRONZE DIAMOND FILIGREE WRAPS A5 (10 rows)
It's important to note, that generated ranges will most likely not be exact 100,000 rows, because some values are more common than others:
$ select title, count(*) from test group by 1 order by count desc limit 10; title | count ------------------------------------------+------- RESERVED | 5058 Earrings | 4879 Modern Abstract Huge Canvas Oil Painting | 4788 Necklace | 4566 Reserved Listing | 3551 Reserved | 3089 Custom Listing | 2930 Custom Order | 2925 Bracelet | 2848 Pretty in Pink | 2791 (10 rows)
But anyway – it seems that if we'd use the values from just_index as base for our counts, it would be pretty good distribution.
So, the “100 Dollars Ceramics Gift Certificate" values – means that there are 100,000 rows, which title, ordered alphabetically, are equal or smaller than “100 Dollars Ceramics Gift Certificate".
There is one slight problem with it – the last row in just_index is:
$ select * from just_index order by title desc limit 1; title ---------------------------------- Zipper Upgrade for your Mims Bag (1 row)
But this is not the last value in original table:
$ select count(*) from test where title > 'Zipper Upgrade for your Mims Bag'; count ------- 48186 (1 row)
There are still 48k rows after it. Do be able to count them, I will insert special value in just_index – which will be with “title is null", and it will be representing all rows that are after last not-null value from just_index:
$ insert into just_index (title) values (null);
Now, we will need to store the counts for every range. So, first we need a place where to store it:
$ alter TABLE just_index add column rowcount int4;
And now update to get the counts. Well, I could write some super-clever query that would so the update in single run, but it's pretty pointless, as it would:
- be relatively slow
- wouldn't be reusable for other purposes
- wouldn't let me speed it up by parallelization
So, instead, let's write simple function, that will set correct count for given subgroup:
CREATE OR REPLACE FUNCTION get_current_real_count( p_partition TEXT ) RETURNS INT4 as $$ DECLARE v_previous TEXT; v_count INT4; BEGIN IF p_partition IS NULL THEN -- That's the last partition SELECT max(title) INTO v_previous FROM just_index; EXECUTE 'SELECT count(*) FROM test WHERE title > $1' INTO v_count USING v_previous; ELSE SELECT title INTO v_previous FROM just_index WHERE title < p_partition ORDER BY title DESC LIMIT 1; IF v_previous IS NULL THEN -- This is the first partition EXECUTE 'SELECT count(*) FROM test WHERE title <= $1' INTO v_count USING p_partition; ELSE EXECUTE 'SELECT count(*) FROM test WHERE title <= $1 AND title > $2' INTO v_count USING p_partition, v_previous; END IF; END IF; RETURN v_count; END; $$ language plpgsql;
You might wonder why I used dynamic queries (EXECUTE) – reason is very simple, without them, we'd fell in the prepares statements gotcha that I wrote about some time ago. And this is definitely something we'd prefer to avoid.
Having this function, I can easily:
$ update just_index set rowcount = get_current_real_count( title );
But I could also do some tricks to run it in parallel – for example like this:
psql -c 'SELECT quote_nullable( title ) from just_index' -qAtX | \ xargs -d"\n" -I{} -P3 \ psql -c "update just_index set rowcount = get_current_real_count( {} ) WHERE not ( title is distinct from {} )"
Which will run the updates, in parallel, each update doing single partition/range/group, and there will be 3 concurrent updates. Thanks to this, I did the whole count/update in ~ 3 minutes.
How does the just_index table look now? First, let's do sanity check. As you remember I have in total 63,748,218 rows in test table. If I did the function correctly, sum of counts should give the same value:
$ select sum(rowcount) from just_index ; sum ---------- 63748218 (1 row)
Additional benefit – getting count of all rows now takes < 0.5ms, and not 10s! One additional thought - the just_index table is small ( 128kB ), but still, I'll need 2 indexes, to make sure that the rows make sense:
$ create unique index just_index_1 on just_index ( title ) where title is not null; CREATE INDEX $ create unique index just_index_2 on just_index ( ( title is null ) ) where title is null; CREATE INDEX
Thanks to this, I will be sure, that all titles are unique in index, including the “fake" NULL.
So, let's write some function to actually get me Nth page of results. But before, simple view that will simplify some calculations/queries:
CREATE VIEW just_index_cumulative_skip AS SELECT sum(rowcount) over (ORDER BY title) - rowcount as skipped, rowcount, lag(title) over (ORDER BY title) as group_start, title as group_end FROM just_index ;
Data from it looks like this:
skipped | rowcount | group_start | group_end
---------+----------+-----------------------------------------------+-------------------------------------------------------------------------------------------------------------------------
0 | 100001 | [null] | 100 Dollars Ceramics Gift Certificate
100001 | 99999 | 100 Dollars Ceramics Gift Certificate | 100pcs light yellow and bule flowers D1.5cm
200000 | 100002 | 100pcs light yellow and bule flowers D1.5cm | 100% wool shrug for Tonner, Cami, or Ellowyne
300002 | 100003 | 100% wool shrug for Tonner, Cami, or Ellowyne | 10 Feet Silver Mother-Son Chains CHSM020Y-S
400005 | 99995 | 10 Feet Silver Mother-Son Chains CHSM020Y-S | 10% OFF SALE VTG SOLID BRONZE RARE TRINITARIAN MEDAL CROSS CRUCIFIX FOR ROSARY RELIGIOUS JEWELRY CROSS PENDANT NECKLACE
(5 rows)With this in place, I can write the function to return paged results:
CREATE OR REPLACE FUNCTION get_nth_page( p_page INT4, p_pagesize INT4) RETURNS SETOF TEXT as $$ DECLARE v_offset INT4 := ( p_page - 1 ) * p_pagesize; v_group RECORD; v_initial TEXT; BEGIN -- Find which group should we scan to get the requested page SELECT * INTO v_group FROM just_index_cumulative_skip WHERE skipped <= v_offset ORDER BY skipped desc LIMIT 1; IF NOT FOUND THEN RAISE EXCEPTION 'Something bad happened - perhaps negative page number?'; END IF; -- Modify offset, based on number of rows skipped in groups. v_offset := v_offset - v_group.skipped; -- Sanity check IF v_offset > v_group.rowcount THEN raise exception 'Given page number doesn''t make sense - it''s past total number of pages.'; END IF; -- Scanning from beginning of group. It's cheaper than scanning from the end, so we switch after 66%, and not after half. IF v_offset::float8 < ( v_group.rowcount::float8 * 0.66 ) THEN -- Looking forward from lower end of range. IF v_group.group_start IS NULL THEN -- This is in the first range, so we have no where at all. RETURN QUERY EXECUTE 'SELECT title FROM test ORDER BY title ASC LIMIT $1 OFFSET $2' USING p_pagesize, v_offset; ELSE -- Skipping some ranges, and then using offset to get final page. RETURN QUERY EXECUTE 'SELECT title FROM test WHERE title > $1 ORDER BY title ASC LIMIT $2 OFFSET $3' USING v_group.group_start, p_pagesize, v_offset; END IF; RETURN; END IF; IF v_offset + p_pagesize <= v_group.rowcount THEN -- This means that the whole page fits in current group. v_offset := v_group.rowcount - ( p_pagesize + v_offset ); IF v_group.group_end IS NULL THEN -- Last group - with end mark being NULL RETURN QUERY EXECUTE 'SELECT title FROM (SELECT title FROM test ORDER BY title DESC LIMIT $1 OFFSET $2) as x ORDER BY title' USING p_pagesize, v_offset; ELSE -- NOT last group RETURN QUERY EXECUTE 'SELECT title FROM (SELECT title FROM test WHERE title <= $1 ORDER BY title DESC LIMIT $2 OFFSET $3) as x ORDER BY title' USING v_group.group_end, p_pagesize, v_offset; END IF; RETURN; END IF; -- Since not every row in requested page fits in current group, we need to return rows using 2 separate queries. -- First, whatever we can return from current page: IF v_group.group_end IS NULL THEN -- Last group - with end mark being NULL RETURN QUERY EXECUTE 'SELECT title FROM (SELECT title FROM test ORDER BY title DESC LIMIT $1) as x ORDER BY title' USING p_pagesize, v_group.rowcount - v_offset; -- If it was last group, there IS no point in searching past it. RETURN; ELSE -- NOT last group RETURN QUERY EXECUTE 'SELECT title FROM (SELECT title FROM test WHERE title <= $1 ORDER BY title DESC LIMIT $2) as x ORDER BY title' USING v_group.group_end, v_group.rowcount - v_offset; END IF; RETURN QUERY EXECUTE 'SELECT title FROM test WHERE title > $1 ORDER BY title ASC LIMIT $2' USING v_group.group_end, p_pagesize - ( v_group.rowcount - v_offset ); RETURN; END; $$ language plpgsql;
Whoa, this looks ugly. But, it has to be noted that it looks ugly because whenever I have to scan for rows, I have to add some IFs to check whether the current range/group doesn't start or end with NULL, which changes the queries.
Luckily, this can be refactored to helper function:
CREATE OR REPLACE FUNCTION get_nth_page_sql( p_order TEXT, p_boundary TEXT, p_limit INT4, p_offset INT4 ) RETURNS TEXT as $$ DECLARE v_sql TEXT; v_order TEXT := CASE WHEN p_order = 'ASC' THEN 'ASC' ELSE 'DESC' END; v_comparison TEXT := CASE WHEN v_order = 'ASC' THEN '>' ELSE '<=' END; BEGIN v_sql := 'SELECT title FROM test'; IF p_boundary IS NOT NULL THEN v_sql := v_sql || ' WHERE title ' || v_comparison || ' ' || quote_literal( p_boundary ); END IF; v_sql := v_sql || ' ORDER BY TITLE ' || v_order || ' LIMIT ' || p_limit; IF p_offset IS NOT NULL THEN v_sql := v_sql || ' OFFSET ' || p_offset; END IF; IF v_order = 'DESC' THEN RETURN 'SELECT title FROM ( ' || v_sql || ' ) as x ORDER BY title'; END IF; RETURN v_sql; END; $$ language plpgsql;
Which let's me simplify the main function to:
CREATE OR REPLACE FUNCTION get_nth_page( p_page INT4, p_pagesize INT4) RETURNS SETOF TEXT as $$ DECLARE v_offset INT4 := ( p_page - 1 ) * p_pagesize; v_group RECORD; v_initial TEXT; BEGIN -- Find which group should we scan to get the requested page SELECT * INTO v_group FROM just_index_cumulative_skip WHERE skipped <= v_offset ORDER BY skipped desc LIMIT 1; IF NOT FOUND THEN RAISE EXCEPTION 'Something bad happened - perhaps negative page number?'; END IF; -- Modify offset, based on number of rows skipped in groups. v_offset := v_offset - v_group.skipped; -- Sanity check IF v_offset > v_group.rowcount THEN raise exception 'Given page number doesn''t make sense - it''s past total number of pages.'; END IF; -- Scanning from beginning of group. It's cheaper than scanning from the end, so we switch after 66%, and not after half. IF v_offset::float8 < ( v_group.rowcount::float8 * 0.66 ) THEN RETURN QUERY EXECUTE get_nth_page_sql( 'ASC', v_group.group_start, p_pagesize, v_offset ); RETURN; END IF; IF v_offset + p_pagesize <= v_group.rowcount THEN -- This means that the whole page fits in current group. v_offset := v_group.rowcount - ( p_pagesize + v_offset ); RETURN QUERY EXECUTE get_nth_page_sql( 'DESC', v_group.group_end, p_pagesize, v_offset ); RETURN; END IF; -- Since not every row in requested page fits in current group, we need to return rows using 2 separate queries. -- First, whatever we can return from current page: RETURN QUERY EXECUTE get_nth_page_sql( 'DESC', v_group.group_end, v_group.rowcount - v_offset, NULL ); IF v_group.group_end IS NOT NULL THEN -- This was NOT the last group, so there are next rows to fill the page RETURN QUERY EXECUTE get_nth_page_sql( 'ASC', v_group.group_end, p_pagesize - ( v_group.rowcount - v_offset ), NULL ); END IF; RETURN; END; $$ LANGUAGE PLPGSQL;
Results are like this:
$ select * from get_nth_page( 2500, 25 ); get_nth_page --------------------------------------------------- 100 Antique Bronze Crimp Beads 4mm 100 Antique Bronze Crimp Beads 4mm 100 Antique Bronze Crimp Beads 4mm 100 Antique Bronze Crimp Beads 4mm 100 Antique Bronze Crimp Beads 4mm 100 Antique Bronze Crimp Beads 4mm 100 antique bronze dainty 10mm filigree bead caps 100 antique bronze dainty 10mm filigree bead caps 100 antique bronze dainty 10mm filigree bead caps 100 antique bronze dainty 10mm filigree bead caps 100 antique bronze dainty 10mm filigree bead caps 100 antique bronze dainty 10mm filigree bead caps 100 antique bronze dainty 10mm filigree bead caps 100 antique bronze dainty 10mm filigree bead caps 100 antique bronze dainty 10mm filigree bead caps 100 antique bronze dainty 10mm filigree bead caps 100 antique bronze dainty 10mm filigree bead caps 100 antique bronze dainty 10mm filigree bead caps 100 antique bronze dainty 10mm filigree bead caps 100 antique bronze dainty 10mm filigree bead caps 100 antique bronze dainty 10mm filigree bead caps 100 antique bronze dainty 10mm filigree bead caps 100 antique bronze dainty 10mm filigree bead caps 100 antique bronze dainty 10mm filigree bead caps 100 antique bronze dainty 10mm filigree bead caps (25 rows)
This page of results is not really nice, but at the very least it shows that it works.
To verify that it really works fine, I used this Perl script:
#!/usr/bin/perl use strict; use Time::HiRes qw( time ); use DBI; my $dbh = DBI->connect( 'dbi:Pg:dbname=test' ) or die 'oops'; for ( my $page = 1 ; $page < 2549929 ; $page += 100 ) { print "$page,"; my $offset = ( $page - 1 ) * 25; # Precache data my $tmp = $dbh->selectall_arrayref( "SELECT title FROM test ORDER BY title ASC LIMIT 25 OFFSET $offset" ); my $start1 = time(); my $data1 = [ map { $_->[ 0 ] } @{ $dbh->selectall_arrayref( "SELECT title FROM test ORDER BY title ASC LIMIT 25 OFFSET $offset" ) } ]; my $end1 = time(); # Precache data $tmp = $dbh->selectall_arrayref( "SELECT * FROM get_nth_page( $page, 25) " ); my $start2 = time(); my $data2 = [ map { $_->[ 0 ] } @{ $dbh->selectall_arrayref( "SELECT * FROM get_nth_page( $page, 25) " ) } ]; my $end2 = time(); my $time1 = $end1 - $start1; my $time2 = $end2 - $start2; printf "%.2f,%.2f,", $time1, $time2; print is_the_same( $data1, $data2 ) ? "ok\n" : "not ok\n"; } exit; sub is_the_same { my ( $a1, $a2 ) = @_; return unless scalar( @{ $a1 } ) == scalar( @{ $a2 } ); for my $i (0.. $#{ $a1 } ) { return if $a1->[$i] ne $a2->[$i]; } return 1; }
It's output is simply:
1,0.00,0.00,ok 101,0.00,0.00,ok 201,0.00,0.00,ok 301,0.01,0.01,ok 401,0.01,0.01,ok ...
If the page returns by limit/offset would be different from the page returns by my function, it would be “not ok" in last column. Luckily – it's always “ok".
Now, for the performance check. I modified the Perl script, to test the same pages that I previously checked with shell/psql. Result:
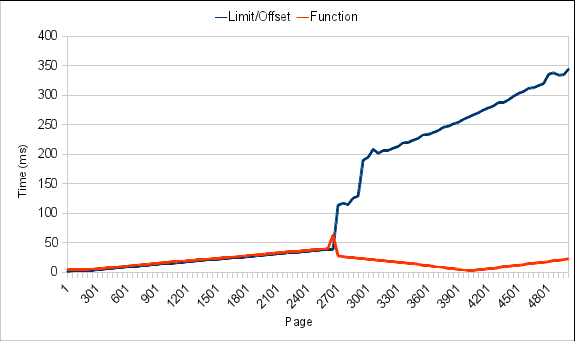
Looks pretty sweet – I'm not testing it for pages later on because LIMIT/OFFSET approach is getting prohibitively expensive, but you can (I think) see that the procedural approach is much nicer.
Now, let's think a bit about maintenance of the system.
To make it fully work, we need to know exact counts of elements in each group/range.
This is relatively easy task, but one that can lead to problems.
Why?
Let's imagine that we will add a trigger that increments the counter. Now, for the sake of simplicity, let's assume our borders of ranges are single letters only. So I have ranges defined by: a,b,c,d,e,f,g, ….
Now. Connection #1 opens transaction, and inserts object with title “Anaconda". This obviously increments counter for “a".
But now, let's assume that the transaction that inserted this object gets stalled – it doesn't commit/rollback. Perhaps it reached out to some other system which was hanging, perhaps it needed to calculate something complicated – reason is irrelevant. What is relevant is the fact that we have long-lived transaction, with lock on group “a", that locks all other writes to this group.
So, if connection #2, will try to insert object with title “American Beauty" – it will have to wait for the lock from first transaction.
This kind of situation is, of course, application error – transaction shouldn't be kept longer than necessary. But not all errors can be easily fixed.
So, what can we do about it?
Let's make the counter increment asynchronous. To make it work like this, we will need:
- Queue table, to keep all, not yet processed, increment/decrement events
- Triggers that will store the events in queue
- Queue processor
First part is trivial:
create table just_index_queue ( title text, change int4 );
This was simple. Now for the triggers.
Before I'll write the actual triggers, I'll first add helper function, which will return group title that given title should be assigned to. It's very simple, but will let me avoid repeating code in trigger functions:
CREATE OR REPLACE FUNCTION get_group_title( TEXT ) RETURNS TEXT as $$ SELECT title FROM just_index WHERE title > $1 ORDER BY title ASC LIMIT 1; $$ language sql;
Told you that's simple. Simple check:
$ select t.word, j.group_start, j.group_end from ( values ('hubert'), ('depesz'), ('lubaczewski'), ('aaa'), ('zzz') ) as t(word) join just_index_cumulative_skip j on NOT (get_group_title( t.word) IS DISTINCT FROM j.group_end ) order by t.word; word | group_start | group_end -------------+----------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------- aaa | 9mm BLUE Translucent Animal Safety eyes 5 PAIRS | ABC on Vintage letter 1 inch Circles Download and Print - Adidit digital collage sheet 080 depesz | Deluxe Boutique Fall Tutu Fairy Costume | Design your own 'PEASANT TOP' - Pick the size Newborn up to 12 Years - by Boutique Mia hubert | Hot pink hoops earrings with pink lucite roses | HUGE Black Friday Sale, ENTIRE Store up to 50 Percent OFF, Pet Deer Skirt, Michael Miller, Fall, Christmas, Winter, 12 18 2 3 4 5 6 lubaczewski | LSU TIGERS Inspired Wedding Garter Set with Marabou Pouf | Lunchbox Notecards zzz | Zipper Upgrade for your Mims Bag | [null] (5 rows)
Looks good. With this function in place, I can add my triggers. I could add single trigger, but I prefer simpler functions:
On-insert trigger:
CREATE OR REPLACE FUNCTION test_index_queue_i() RETURNS TRIGGER AS $$ BEGIN INSERT INTO just_index_queue (title, change) VALUES ( get_group_title( NEW.title ), 1 ); RETURN NEW; END; $$ language plpgsql; CREATE TRIGGER test_index_queue_i AFTER INSERT ON test FOR EACH ROW EXECUTE PROCEDURE test_index_queue_i();
On-delete trigger:
CREATE OR REPLACE FUNCTION test_index_queue_d() RETURNS TRIGGER AS $$ BEGIN INSERT INTO just_index_queue (title, change) VALUES ( get_group_title( OLD.title ), -1 ); RETURN OLD; END; $$ language plpgsql; CREATE TRIGGER test_index_queue_d AFTER DELETE ON test FOR EACH ROW EXECUTE PROCEDURE test_index_queue_d();
And the most complex – on update:
CREATE OR REPLACE FUNCTION test_index_queue_u() RETURNS TRIGGER AS $$ DECLARE v_old_group TEXT; v_new_group TEXT; BEGIN IF NOT NEW.title IS DISTINCT FROM OLD.title THEN RETURN NEW; END IF; v_old_group := get_group_title( OLD.title ); v_new_group := get_group_title( NEW.title ); IF ( NOT v_old_group IS DISTINCT FROM v_new_group ) THEN RETURN new; END IF; INSERT INTO just_index_queue (title, change) VALUES ( v_old_group, -1 ), ( v_new_group, 1 ); RETURN NEW; END; $$ language plpgsql; CREATE TRIGGER test_index_queue_u AFTER UPDATE ON test FOR EACH ROW EXECUTE PROCEDURE test_index_queue_u();
Quick note on the update trigger function. In my test case, I could skip the first check – whether title has been updated – but in reality you want it, to avoid getting group_title's where update doesn't change title at all.
Please note that these functions do just inserts – which means no locking, and very fast execution. Of course getting group title can take some time, but just_index table will be usually very small, so we can ignore it – after all, it's just 200kB (including indexes) when my base table has 60+M rows!.
Addition of those trigger functions mean two things:
- We now need a way to rollup data from _queue table to normal “just_index"
- Our stats in “just_index" are no longer accurate, which means the paging can be broken.
First, as for rolling up data from queue. Another simple function:
CREATE OR REPLACE FUNCTION update_just_index_from_queue() RETURNS void as $$ WITH clean_queue as ( DELETE FROM just_index_queue RETURNING * ), summarized_changes as ( SELECT title, sum(change) FROM clean_queue GROUP BY title HAVING sum(change) <> 0 ) UPDATE just_index as i SET rowcount = i.rowcount + c.sum FROM summarized_changes c WHERE ( c.title IS NOT NULL AND c.title = i.title ) OR ( c.title IS NULL AND i.title IS NULL ); $$ language sql;
This function should be ran from cronjob, quite often, but it shouldn't be ran in parallel, because it could get deadlocked. Of course it's perfectly possible to write a parallelizable version of the function, but for now, I just don't really care. If you'd run it often enough you shouldn't have any problems with it.
One note – this function uses feature from PostgreSQL 9.1 – writable CTE. If you're using something pre-9.1, you will need to rewrite it in some way, but that's left as an exercise for readers/users.
Running this function is trivial:
$ SELECT update_just_index_from_queue(); update_just_index_from_queue ------------------------------ [null] (1 row)
That's all. So, let's see if it actually does it's job. I'll insert some rows, and we'll see if the calculations will be OK. First, base counts:
$ select j.rowcount, t.word, j.title from ( values ('000000000'), ('hubert'), ('depesz'), ('lubaczewski'), ('zzz') ) as t(word) join just_index j on NOT (get_group_title( t.word) IS DISTINCT FROM j.title ) order by t.word; rowcount | word | title ----------+-------------+------------------------------------------------------------------------------------------------------------------------------------- 100001 | 000000000 | 100 Dollars Ceramics Gift Certificate 100000 | depesz | Design your own 'PEASANT TOP' - Pick the size Newborn up to 12 Years - by Boutique Mia 100000 | hubert | HUGE Black Friday Sale, ENTIRE Store up to 50 Percent OFF, Pet Deer Skirt, Michael Miller, Fall, Christmas, Winter, 12 18 2 3 4 5 6 99982 | lubaczewski | Lunchbox Notecards 48186 | zzz | [null] (6 rows)
I choose the test words so that we got first group, last group, and some groups in the middle.
OK. So let's inser some rows:
$ insert into test ( title) values (‘hubert'),(‘depesz'),(‘lubaczewski');
INSERT 0 3
Now, let's run queue updater, and let's see the value afterwards:
$ SELECT update_just_index_from_queue(); update_just_index_from_queue ------------------------------ [null] (1 row) $ select j.rowcount, t.word, j.title from ( values ('000000000'), ('hubert'), ('depesz'), ('lubaczewski'), ('zzz') ) as t(word) join just_index j on NOT (get_group_title( t.word) IS DISTINCT FROM j.title ) order by t.word; rowcount | word | title ----------+-------------+------------------------------------------------------------------------------------------------------------------------------------- 100001 | 000000000 | 100 Dollars Ceramics Gift Certificate 100001 | depesz | Design your own 'PEASANT TOP' - Pick the size Newborn up to 12 Years - by Boutique Mia 100001 | hubert | HUGE Black Friday Sale, ENTIRE Store up to 50 Percent OFF, Pet Deer Skirt, Michael Miller, Fall, Christmas, Winter, 12 18 2 3 4 5 6 99983 | lubaczewski | Lunchbox Notecards 48186 | zzz | [null] (5 rows)
All 3 ranges in the middle seem to update properly. So let's see some updates and deletes:
$ update test set title = '000000000' where title = 'depesz'; UPDATE 1 $ update test set title = 'zzz' where title = 'hubert'; UPDATE 1 $ delete from test where title = 'lubaczewski'; DELETE 1 $ select update_just_index_from_queue(); update_just_index_from_queue ------------------------------ [null] (1 row) $ select j.rowcount, t.word, j.title from ( values ('000000000'), ('hubert'), ('depesz'), ('lubaczewski'), ('zzz') ) as t(word) join just_index j on NOT (get_group_title( t.word) IS DISTINCT FROM j.title ) order by t.word; rowcount | word | title ----------+-------------+------------------------------------------------------------------------------------------------------------------------------------- 100002 | 000000000 | 100 Dollars Ceramics Gift Certificate 100000 | depesz | Design your own 'PEASANT TOP' - Pick the size Newborn up to 12 Years - by Boutique Mia 100000 | hubert | HUGE Black Friday Sale, ENTIRE Store up to 50 Percent OFF, Pet Deer Skirt, Michael Miller, Fall, Christmas, Winter, 12 18 2 3 4 5 6 99982 | lubaczewski | Lunchbox Notecards 48187 | zzz | [null] (5 rows)
All looks fine – rowcounts were changed in sensible way.
Now, that we know how to update the rowcounts in just_index, what can we do about the rowcounts not being right in the mean time?
Luckily, thanks to the fact that in paging function we used view (just_index_cumulative_skip), and not just_index table directly – it's pretty simple to do/fix. We just change definition of the view to:
CREATE VIEW just_index_cumulative_skip AS SELECT sum(i.rowcount + coalesce( q.sum, 0 ) ) over (ORDER BY i.title) - rowcount as skipped, i.rowcount + coalesce( q.sum, 0) as rowcount, lag(i.title) over (ORDER BY i.title) as group_start, i.title as group_end FROM just_index i left outer join ( SELECT title, sum(change) FROM just_index_queue GROUP BY title ) as q ON ( i.title IS NULL AND q.title IS NULL ) OR ( i.title = q.title ) ;
Let's see if it works:
$ insert into test ( title) values ('hubert'),('depesz'),('lubaczewski'),('000000000'), ('zzz'); INSERT 0 5 $ select j.rowcount, t.word, j.title from ( values ('000000000'), ('hubert'), ('depesz'), ('lubaczewski'), ('zzz') ) as t(word) join just_index j on NOT (get_group_title( t.word) IS DISTINCT FROM j.title ) order by t.word; rowcount | word | title ----------+-------------+------------------------------------------------------------------------------------------------------------------------------------- 100002 | 000000000 | 100 Dollars Ceramics Gift Certificate 100000 | depesz | Design your own 'PEASANT TOP' - Pick the size Newborn up to 12 Years - by Boutique Mia 100000 | hubert | HUGE Black Friday Sale, ENTIRE Store up to 50 Percent OFF, Pet Deer Skirt, Michael Miller, Fall, Christmas, Winter, 12 18 2 3 4 5 6 99982 | lubaczewski | Lunchbox Notecards 48187 | zzz | [null] (5 rows) $ select * from just_index_queue ; title | change -------------------------------------------------------------------------------------------------------------------------------------+-------- HUGE Black Friday Sale, ENTIRE Store up to 50 Percent OFF, Pet Deer Skirt, Michael Miller, Fall, Christmas, Winter, 12 18 2 3 4 5 6 | 1 Design your own 'PEASANT TOP' - Pick the size Newborn up to 12 Years - by Boutique Mia | 1 Lunchbox Notecards | 1 100 Dollars Ceramics Gift Certificate | 1 [null] | 1 (5 rows) $ select j.rowcount, t.word, j.group_end from ( values ('000000000'), ('hubert'), ('depesz'), ('lubaczewski'), ('zzz') ) as t(word) join just_index_cumulative_skip j on NOT (get_group_title( t.word) IS DISTINCT FROM j.group_end ) order by t.word; rowcount | word | group_end ----------+-------------+------------------------------------------------------------------------------------------------------------------------------------- 100003 | 000000000 | 100 Dollars Ceramics Gift Certificate 100001 | depesz | Design your own 'PEASANT TOP' - Pick the size Newborn up to 12 Years - by Boutique Mia 100001 | hubert | HUGE Black Friday Sale, ENTIRE Store up to 50 Percent OFF, Pet Deer Skirt, Michael Miller, Fall, Christmas, Winter, 12 18 2 3 4 5 6 99983 | lubaczewski | Lunchbox Notecards 48188 | zzz | [null] (5 rows)
As we can see the rowcounts are nicely incremented.
Now, after all of this, we have a nice solution, which:
- let's me get total count of rows very fast (select sum(rowcount) from just_index_cumulative_skip)
- let's me get any page in near-constant time
- is not limited to any specific number of pages
The only thing left is – what to do after we'll add more data to database, and some of the ranges are simply too big?
That's simple – split the large ranges into smaller ones.
How to do it? Procedure is pretty simple:
- Disable cronjob running rollups of just_index_queue
- Insert into just_index new range divider
- Start transaction in serializable isolation level
- delete all rows in queue which relate to both groups – the old, large one, and the new, smaller one
- calculate correct rowcounts for both groups, and update it in just_index table
- commit transaction
- re-enable queue rollup cronjob
First insert has to happen in another transaction, and be committed before we'll start on fixing counts.
Thanks to this approach, we will have bad counts, but only in the short time between adding new group, and committing transaction with changed counts.
And because all those groups are relatively small, it should be very quick.
Let's see how it works:
$ select * from just_index where title = get_group_title('a'); title | rowcount --------------------------------------------------------------------------------------------+---------- ABC on Vintage letter 1 inch Circles Download and Print - Adidit digital collage sheet 080 | 100000 (1 row)
This is our start. Let's assume we'll insert new group with title ‘a'. So, let's run some queries, with timing information:
$ INSERT INTO just_index (title) VALUES ('a'); INSERT 0 1 Time: 0.393 ms $ BEGIN; BEGIN Time: 0.133 ms $ SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; SET Time: 0.115 ms $ DELETE FROM just_index_queue WHERE title in ('a', 'ABC on Vintage letter 1 inch Circles Download AND Print - Adidit digital collage sheet 080'); DELETE 0 Time: 0.238 ms $ UPDATE just_index SET rowcount = get_current_real_count('a') WHERE title = 'a'; UPDATE 1 Time: 35.990 ms $ UPDATE just_index SET rowcount = get_current_real_count('ABC on Vintage letter 1 inch Circles Download and Print - Adidit digital collage sheet 080') where title = 'ABC on Vintage letter 1 inch Circles Download and Print - Adidit digital collage sheet 080'; UPDATE 1 Time: 285.944 ms $ COMMIT; COMMIT Time: 0.148 ms
And rowcounts for splitted groups:
$ select * from just_index where title in ('a','ABC on Vintage letter 1 inch Circles Download and Print - Adidit digital collage sheet 080'); title | rowcount --------------------------------------------------------------------------------------------+---------- a | 25878 ABC on Vintage letter 1 inch Circles Download and Print - Adidit digital collage sheet 080 | 74122 (2 rows)
Of course it would be better to split more equally, but since that's just an example – it doesn't really matter.
So that wraps it. Hope you'll find it useful.
Pretty useful post. Thanks.
Oh, now i am really scared. >__<
@Wildraid: why?
Interesting, but it seems like an awful lot to do per column I want to sort on.
But the real deal breaker for me is it doesn’t allow for filtering. As soon as I add a filter, and am not selecting all rows, this scheme breaks down.
So I’m probably better off with the previous article, and using WHERE (sorting column, id) > (?, ?) instead of LIMIT. I lose jumping to arbitrary pages, (or have to fall back to limit/offset) but at least I can add arbitrary additional filters to my WHERE clause.