A while ago someone wrote on irc that PostgreSQL has built in hard limit to number of partitions. This tweet was linked as a source of this information.
Decided to check it.
First, let's check the claim itself. Using simple psql script:
$ CREATE TABLE test_ranged ( id serial PRIMARY KEY, payload TEXT ) partition BY range (id); $ select format('CREATE TABLE %I partition OF test_ranged FOR VALUES FROM (%s) to (%s);', 'test_ranged_' || i, i, i+1) FROM generate_series(1,10000) i \gexec $ select format('CREATE TABLE %I partition OF test_ranged FOR VALUES FROM (%s) to (%s);', 'test_ranged_' || i, i, i+1) FROM generate_series(10001, 20000) i \gexec $ select format('CREATE TABLE %I partition OF test_ranged FOR VALUES FROM (%s) to (%s);', 'test_ranged_' || i, i, i+1) FROM generate_series(20001, 30000) i \gexec $ select format('CREATE TABLE %I partition OF test_ranged FOR VALUES FROM (%s) to (%s);', 'test_ranged_' || i, i, i+1) FROM generate_series(30001, 40000) i \gexec $ select format('CREATE TABLE %I partition OF test_ranged FOR VALUES FROM (%s) to (%s);', 'test_ranged_' || i, i, i+1) FROM generate_series(40001, 50000) i \gexec $ select format('CREATE TABLE %I partition OF test_ranged FOR VALUES FROM (%s) to (%s);', 'test_ranged_' || i, i, i+1) FROM generate_series(50001, 60000) i \gexec $ select format('CREATE TABLE %I partition OF test_ranged FOR VALUES FROM (%s) to (%s);', 'test_ranged_' || i, i, i+1) FROM generate_series(60001, 70000) i \gexec
Each of these select format queries outputted lines like:
$ select format('CREATE TABLE %I partition OF test_ranged FOR VALUES FROM (%s) to (%s);', 'test_ranged_' || i, i, i+1) FROM generate_series(1,5) i; format --------------------------------------------------------------------------------- CREATE TABLE test_ranged_1 partition OF test_ranged FOR VALUES FROM (1) to (2); CREATE TABLE test_ranged_2 partition OF test_ranged FOR VALUES FROM (2) to (3); CREATE TABLE test_ranged_3 partition OF test_ranged FOR VALUES FROM (3) to (4); CREATE TABLE test_ranged_4 partition OF test_ranged FOR VALUES FROM (4) to (5); CREATE TABLE test_ranged_5 partition OF test_ranged FOR VALUES FROM (5) to (6); (5 rows)
and then I feed it to \gexec which runs each of these queries.
With the script above I made 70,000 partitions:
$ select count(*) from pg_class where relkind = 'r' and relname ~ '^test_ranged_[0-9]*$'; count ------- 70000 (1 row)
Clearly, the limit to ~ 65000 is not there. But perhaps it will show problem when I'll try to select …
$ explain select * from test_ranged where id = 1; QUERY PLAN ───────────────────────────────────────────────────────────────────────────────────────────────────── Index Scan using test_ranged_1_pkey on test_ranged_1 test_ranged (cost=0.15..8.17 rows=1 width=36) Index Cond: (id = 1) (2 rows) $ explain select * from test_ranged where id = 68000; QUERY PLAN ───────────────────────────────────────────────────────────────────────────────────────────────────────────── Index Scan using test_ranged_68000_pkey on test_ranged_68000 test_ranged (cost=0.15..8.17 rows=1 width=36) Index Cond: (id = 68000) (2 rows)
Looks like the limit is not really there, at least not for ~ 65000 partitions.
Obviously I could create more partitions, and check if/when it will break, but I think that 65k partitions really should be enough.
But now, let's see if this number of partitions is reasonable.
To do it, I'll do something like this:
$ explain analyze select * from test_ranged where id = _SOME_ID_;
with ‘_SOME_ID_' being one of:
- ~ 5% of partition count
- ~ 25% of partition count
- ~ 50% of partition count
- ~ 95% of partition count
Each test will be ran three times, and I'll note best and worst planning time, and best and worst execution time.
Each test query will be run in separate session, so that effect of caching will be reduced to minimum.
After each test, I'll remove last 9500 partitions, to see how how it behaves with different numbers of partitions.
What I quickly saw is that execution time is negligible (less than 0.1ms). And differences between best and worst did cross 20%, I think it was more related to outside factors. So let's focus on best time for planning:
| Partitions | Planning time for test % | |||
|---|---|---|---|---|
| 5% | 25% | 50% | 95% | |
| 3500 | 21.276 | 23.850 | 21.304 | 20.761 |
| 13000 | 81.483 | 81.666 | 81.551 | 81.069 |
| 22500 | 142.176 | 143.636 | 143.613 | 142.775 |
| 32000 | 206.930 | 211.370 | 212.274 | 206.516 |
| 41500 | 276.406 | 279.998 | 273.119 | 279.261 |
| 51000 | 353.771 | 392.577 | 346.140 | 341.415 |
| 60500 | 400.081 | 407.418 | 400.520 | 401.447 |
| 70000 | 458.937 | 461.512 | 468.936 | 459.724 |
which can be clearer as a graph:
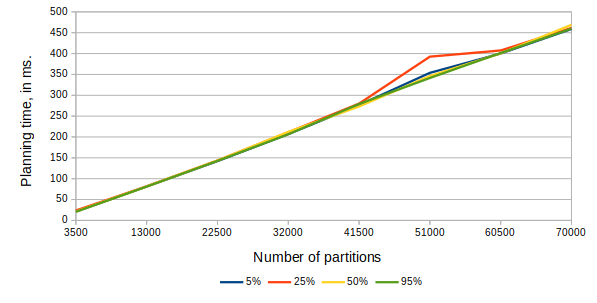
Basically, it looks that planning time is linearly dependent on number of partitions.
Of course, in real life scenarios, partitions would be wider, and have more rows, so execution time would be more important. But it's good to note that picking appropriate partition is not free.
Based on what I see in here, I can imagine an improvement for scanning list of partitions to use some kind of tree, which should make the O(n) into O(log n) or something like this.
As a final though, I decided to let the computer running for longer time and make even more partitions:
$ \d test_ranged
Partitioned table "public.test_ranged"
Column │ Type │ Collation │ Nullable │ Default
─────────┼─────────┼───────────┼──────────┼─────────────────────────────────────────
id │ integer │ │ not null │ nextval('test_ranged_id_seq'::regclass)
payload │ text │ │ │
Partition key: RANGE (id)
Indexes:
"test_ranged_pkey" PRIMARY KEY, btree (id)
Number of partitions: 200000 (Use \d+ to list them.)Querying it, as expected, works.
$ explain analyze select * from test_ranged where id = 195765; QUERY PLAN ───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── Index Scan using test_ranged_195765_pkey on test_ranged_195765 test_ranged (cost=0.15..8.17 rows=1 width=36) (actual time=0.005..0.005 rows=0 loops=1) Index Cond: (id = 195765) Planning Time: 571.054 ms Execution Time: 0.022 ms (4 rows)
So where does that leave us? Well, partitioning is great. It routinely simplifies DBA tasks by splitting maintenance into smaller bits. And it can greatly speed up queries if they match the criteria of partitioning.
I would probably discourage people from making 5000+ partitions of single table, but Pg can definitely handle it.
This depends on version of PostgreSQL. PostgreSQL 12 is significantly better than older releases, and 13 did some progress too. The bad planning time is one thing, second thing can be memory consumption. The users reported “out of memory” issues.
Hi Hubert,
Great, I like when things are tested 🙂
Did you measure the partition pruning time when done at execution time (Subplans Removed from a prepared generic plan)? It may be the same, but I think that if a use case comes for thousands of partitions (hash partition key probably, to scale like NoSQL key-value stores) it should use prepared statements kept in a connection pool and pruned by the executor. Of course this is still limited as it works only for SELECT.
You are mentioning O(n) for pruning, but I see in https://www.enterprisedb.com/postgres-tutorials/partition-pruning-during-executionpartition-pruning-during-execution that: “Initially, in V10 the undesirable partitions were eliminated by a tedious linear search in the planner but with V11, this has been updated to quicker a binary search of the list.”, is that right?
Franck.
Hi, content on this site is awesome, could we make it more readable on mobile devices.
@Franck:
I was doing my tests on Pg 14.
@Arjun:
sorry, it just doesn’t matter all that much for me.
Thanks for the testing. However, there is (at least on version 11) a trap called:
Failed to fetch row: ERROR: out of shared memory
HINT: You might need to increase max_locks_per_transaction.
The more partitions and concurrent users of the partitioned table the fixed locks spaces will be exhausted.
And second, the indirect impact from high concurrency is significant pressure for the lock manager, I’ve seen thousands of waits for lock manager and corresponding CPU utilization and transaction throughput degradation since all the partitions need LW lock to ensure they will not be dropped/altered during another query execution. So for high concurrency in access to a partitioned table, I’ll suggest way fewer partitions to be used.
@Aleš:
well, increase max_locks_per_transaction then. I never said that it can be done on *any* configuration. It’s just that there is no particular limit (or at least not as low as ~60k) in PostgreSQL.
There is actually a limit in the planner on the number of tables/partitions it can handle in a query. You can see it like this:
postgres=# set plan_cache_mode to force_generic_plan;
SET
postgres=# prepare q as select * from test_ranged where id = $1;
PREPARE
postgres=# explain execute q (1);
ERROR: too many range table entries
I think the linked tweet talks about this limit.
@Amit:
that’s interesting. Haven’t thought of it.
Still – the limit is on number of tables/partitions you can use per query, and not on number of partition you can have.
Thank you very much for this deep investigation.
I see a lot of people telling we should not use too much sub partition tables.
You also mention we should not make 5000+ partitions of single table.
But why? I never see the explanation. Would that be for performance reasons? Or is it a bad pattern?
In my company we currently want to create ~45000 subpartitions tables based from a single table. And this number will keep growing.
Partition table will be done against LIST with one entry which is an Id.
We do this, because this is the only way to get better performances for our queries when dealing with +70 millions of record. Indeed psql query plan uses a parallel query, instead of an index. Using subpartition tables did the trick.
So, in the end, why not using +5000 subpartition tables?
@Guillaume:
Not sure. I don’t know details of your situation, and queries, so can’t comment. If this schema works for you – great. I would be worried about increased cost of planning queries, and certain maintenance tasks (upgrades come to mind), but, again – if it works for you – great.