some time ago i wrote about potential (or not potential, depending on your situation) problem with updates which do not update anything.
now, andrew dunstan wrote c version of trigger which skips such updates.
so, let's test how well it works.
so, i created a script which does the test. it contains of several parts.
first part is table creation:
CREATE TABLE test (id serial PRIMARY KEY, column1 INT4, column2 TEXT); CREATE TABLE test_c (id serial PRIMARY KEY, column1 INT4, column2 TEXT); CREATE TABLE test_p (id serial PRIMARY KEY, column1 INT4, column2 TEXT);
then, some inserts:
INSERT INTO test (column1, column2) SELECT i, i::TEXT FROM generate_series(1,100000) i; INSERT INTO test_c (column1, column2) SELECT i, i::TEXT FROM generate_series(1,100000) i; INSERT INTO test_p (column1, column2) SELECT i, i::TEXT FROM generate_series(1,100000) i;
functions creation:
CREATE OR REPLACE FUNCTION min_update_trigger() RETURNS trigger AS 'min_update_trigger' language C; CREATE OR REPLACE FUNCTION prevent_empty_updates() RETURNS trigger as $BODY$ DECLARE BEGIN IF ROW(OLD.*) IS DISTINCT FROM ROW(NEW.*) THEN RETURN NEW; END IF; RETURN NULL; END; $BODY$ language plpgsql;
full cleanup in case something somewhere was touched:
vacuum full analyze; REINDEX TABLE test; REINDEX TABLE test_c; REINDEX TABLE test_p;
trigger creation:
CREATE TRIGGER _min BEFORE UPDATE ON test_p FOR EACH ROW EXECUTE PROCEDURE prevent_empty_updates(); CREATE TRIGGER _min BEFORE UPDATE ON test_c FOR EACH ROW EXECUTE PROCEDURE min_update_trigger();
as you can see – test table doesn't have any triggers, test_p has pl/pgsql version of “protecting" trigger, and test_c is protected using andrews code.
now, before actual timing test, i check table sizes:
SELECT relname, relkind, pg_size_pretty(pg_relation_size(oid)) FROM pg_class WHERE relname ~ '^test';
and then i run the test itself:
UPDATE test SET column1 = column1, column2 = column2; UPDATE test_p SET column1 = column1, column2 = column2; UPDATE test_c SET column1 = column1, column2 = column2;
nothing really fancy 🙂
now i check for table sizes after update:
SELECT relname, relkind, pg_size_pretty(pg_relation_size(oid)) FROM pg_class WHERE relname ~ '^test';
and cleanup database from unneccessary tables:
DROP TABLE test; DROP TABLE test_c; DROP TABLE test_p;
so, how does it go? before i ran it “for real", 100 times, i ran it once to check sizes – just to be sure.
before update sizes are:
relname | relkind | pg_size_pretty ---------------+---------+---------------- test_pkey | i | 1768 kB test_c_pkey | i | 1768 kB test_p_pkey | i | 1768 kB test_p | r | 4328 kB test_c | r | 4328 kB test_c_id_seq | S | 8192 bytes test_id_seq | S | 8192 bytes test | r | 4328 kB test_p_id_seq | S | 8192 bytes (9 rows)
after:
relname | relkind | pg_size_pretty ---------------+---------+---------------- test_pkey | i | 5288 kB test_c_pkey | i | 1768 kB test_p_pkey | i | 1768 kB test_p | r | 4328 kB test_c | r | 4328 kB test_c_id_seq | S | 8192 bytes test_id_seq | S | 8192 bytes test | r | 8648 kB test_p_id_seq | S | 8192 bytes (9 rows)
as you can see, we clearly have increase in case of “unprotected" table, and no increase in both test_c and test_p cases – which was expected 🙂
now, timing. to get somehow “belivable" timings, i ran the tests 100 times.
results?
summarized time of 100 runs on:
- test table (no protection) : 175371 ms
- test_p table (pl/pgsql) : 121846 ms
- test_c table (c) : 57593 ms
whoa.
basically – both protections are faster than no protection at all (which is not surprising), but c version if over 2 times as fast as pl/pgsql version!
now. this is interesting, but what happens when we actually do some update? adding trigger will (obviously) slow things down. how much?
again, same test, but this time, i run updates:
UPDATE test SET column1 = column1 + 1, column2 = column2 || 'x'; UPDATE test_p SET column1 = column1 + 1, column2 = column2 || 'x'; UPDATE test_c SET column1 = column1 + 1, column2 = column2 || 'x';
this time, when i run updates, sizes of tables and indexes rise in all cases:
relname | relkind | pg_size_pretty ---------------+---------+---------------- test_pkey | i | 5288 kB test_c_pkey | i | 5288 kB test_p_pkey | i | 5288 kB test_c_id_seq | S | 8192 bytes test_p | r | 8648 kB test_c | r | 8648 kB test_p_id_seq | S | 8192 bytes test_id_seq | S | 8192 bytes test | r | 8648 kB (9 rows)
and how much slower the triggers are than no-trigger-on-table approach? plus, how much faster c version is in comparison to pl/pgsql? again, i ran the test 100 times.
summarized time of 100 runs on:
- test table (no protection) : 182624 ms
- test_p table (pl/pgsql) : 316734 ms
- test_c table (c) : 296421 ms
wow. not good. in all-updates-are-real scenario (worst case for this triggers) we have 62 to 73% slowdown.
additionally. trigger in c is only 6% faster than plpgsql version (but remember how much faster it was in best case scenario).
now, let's test the speed of the code in various cases – i.e. when we update 10% of rows, 20% of rows, and so on.
results will be shown in a graph below – all times are summarized times of 100 executions of each updated-rows-percentage.
- 10% of rows updated; test: 169090 ms; test_p: 136174 ms; test_c: 70459 ms
- 20% of rows updated; test: 167965 ms; test_p: 157677 ms; test_c: 90043 ms
- 30% of rows updated; test: 168694 ms; test_p: 171299 ms; test_c: 111488 ms
- 40% of rows updated; test: 170504 ms; test_p: 192256 ms; test_c: 134410 ms
- 50% of rows updated; test: 171682 ms; test_p: 208655 ms; test_c: 149712 ms
- 60% of rows updated; test: 177400 ms; test_p: 228300 ms; test_c: 172773 ms
- 70% of rows updated; test: 150965 ms; test_p: 318875 ms; test_c: 154559 ms
- 80% of rows updated; test: 170248 ms; test_p: 267761 ms; test_c: 240563 ms
- 90% of rows updated; test: 169195 ms; test_p: 282442 ms; test_c: 268490 ms
how does it look ?
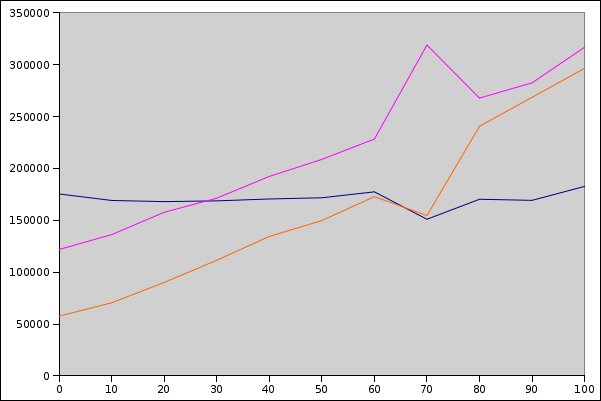
now, i dont understand the bump on 70%, but i redid the test, and it was still there – i have no clue on what it might be. but even when you'll forget it, it seems to be clear that if your empty updates are 40 (or more) percent of all updates – you should at least consider using this c-based trigger.
and remember – this 40% is with very simplictic table layout. only 3 columns. my guess is that the more columns you have (i.e. longer records to write to update), the better the solution with empty-updates-protection 🙂
Interesting results.
I have the feeling this empty-update protection is best used to avoid VACUUM work.
I bet the update protection would have much better results in your graph for steady state performance. The unprotected table would need periodic VACUUMs or would suffer from bloat, in the steady state, whereas the protected table could avoid that.
Were you testing this on 8.2 or the 8.3 RCs? Just wondering with the enhancements in 8.3 how the tests would fair.
@Regina:
8.3rc2, straight from cvs head.
@Jeff Davis:
definitely. even with hot updates in 8.3, the bloat is still there. of course, if i create the table with lower fillfactor, the bloat would be lower, but the overal table size would be the same or a bit higher.
I don’t quite understand what’s going on here. The apparent overhead of setting up and calling the C trigger is something less than 57593 ms. So even if we’re doing 100% updates We should not expect the updates to cost more than this much more with the trigger turned on. The only thing I can think of is that there’s some significant extra cost involved when a trigger succeeds, probably from extra copying of data. If so, that’s a worry. Maybe we need some profiling data.
Another point is this: I really designed the trigger to deal with a situation I have where tables being updated are heavily indexed, and so updates are very expensive. I suspect that the break even point for the C trigger in such a situation will be much closer to 100% than the 65% shown by the figures above, especially on humungous tables that don’t fit in RAM.
@Andrew Dunstan:
as for break-even – of course. i mentioned larger (wider) tables, but you’re absolutely right about indexes and table size in general.
as for calling c trigger – it does look suspicious, but i can’t really help with it. some c programmer with profiling skills would be necessary – of course i will be more than happy to check results/fixes/patches, but as i understand it, substantial gain in this case cannot be made in trigger code, but rather in postgresql itself.
I’m interested in seeing this testing on 9.6 to see if the cost is still the same. It’d also be interested to time vacuum performance.