On 1st of February 2021, Peter Eisentraut committed patch:
SEARCH and CYCLE clauses This adds the SQL standard feature that adds the SEARCH and CYCLE clauses to recursive queries to be able to do produce breadth- or depth-first search orders and detect cycles. These clauses can be rewritten into queries using existing syntax, and that is what this patch does in the rewriter. Reviewed-by: Vik Fearing <vik@postgresfriends.org> Reviewed-by: Pavel Stehule <pavel.stehule@gmail.com> Discussion: https://www.postgresql.org/message-id/flat/db80ceee-6f97-9b4a-8ee8-3ba0c58e5be2@2ndquadrant.com
Just as message suggests this change is related to recursive queries.
Which means, that to test it, we need some data for recursive queries. This time I took directory listing of my /etc, and loaded it to db:
$ create table dirs ( id int NOT NULL, parent_id int REFERENCES dirs (id), dirname text, primary key (id) ); CREATE TABLE $ copy dirs from '/tmp/dirs.data'; COPY 434
Great, we can now see full paths to each dir:
$ WITH RECURSIVE c AS ( SELECT id, dirname AS path FROM dirs WHERE parent_id is null UNION ALL SELECT dirs.id, c.path || '/' || dirs.dirname AS path FROM dirs JOIN c ON dirs.parent_id = c.id ) SELECT id, path FROM c ORDER BY path limit 15; id | path ----+----------------------------- 1 | etc 42 | etc/acpi 43 | etc/acpi/events 44 | etc/alsa 45 | etc/alsa/conf.d 46 | etc/alternatives 47 | etc/apache2 48 | etc/apache2/conf-available 49 | etc/apm 50 | etc/apm/resume.d 51 | etc/apm/scripts.d 52 | etc/apm/suspend.d 53 | etc/apparmor 54 | etc/apparmor.d 55 | etc/apparmor.d/abstractions (15 rows)
Cool. Now let's see what these new changes get us.
First thing is:
$ WITH RECURSIVE c AS ( SELECT id, dirname AS path FROM dirs WHERE parent_id is null UNION ALL SELECT dirs.id, c.path || '/' || dirs.dirname AS path FROM dirs JOIN c ON dirs.parent_id = c.id ) SEARCH DEPTH FIRST BY id SET ordercol SELECT id, path FROM c ORDER BY ordercol limit 15; id | path -----+-------------------------------------------- 1 | etc 2 | etc/.java 434 | etc/.java/.systemPrefs 3 | etc/GNUstep 4 | etc/ImageMagick-6 5 | etc/Muttrc.d 6 | etc/NetworkManager 7 | etc/NetworkManager/conf.d 8 | etc/NetworkManager/dispatcher.d 9 | etc/NetworkManager/dispatcher.d/no-wait.d 10 | etc/NetworkManager/dispatcher.d/pre-down.d 11 | etc/NetworkManager/dispatcher.d/pre-up.d 12 | etc/NetworkManager/dnsmasq.d 13 | etc/NetworkManager/dnsmasq-shared.d 14 | etc/NetworkManager/system-connections (15 rows)
OK. So this returns the dirs, depth first, but ordered by id.
Let's try to get the previous output, ascii-betical order, using this new approach, but also, let's see what ordercol really is:
$ WITH RECURSIVE c AS ( SELECT id, dirname AS path FROM dirs WHERE parent_id is null UNION ALL SELECT dirs.id, c.path || '/' || dirs.dirname AS path FROM dirs JOIN c ON dirs.parent_id = c.id ) SEARCH DEPTH FIRST BY path SET ordercol select id, path, ordercol from c order by ordercol limit 15; id | path | ordercol ----+----------------------------------------------+------------------------------------------------------------------------------------------- 1 | etc | {(etc)} 42 | etc/acpi | {(etc),(etc/acpi)} 43 | etc/acpi/events | {(etc),(etc/acpi),(etc/acpi/events)} 44 | etc/alsa | {(etc),(etc/alsa)} 45 | etc/alsa/conf.d | {(etc),(etc/alsa),(etc/alsa/conf.d)} 46 | etc/alternatives | {(etc),(etc/alternatives)} 47 | etc/apache2 | {(etc),(etc/apache2)} 48 | etc/apache2/conf-available | {(etc),(etc/apache2),(etc/apache2/conf-available)} 49 | etc/apm | {(etc),(etc/apm)} 50 | etc/apm/resume.d | {(etc),(etc/apm),(etc/apm/resume.d)} 51 | etc/apm/scripts.d | {(etc),(etc/apm),(etc/apm/scripts.d)} 52 | etc/apm/suspend.d | {(etc),(etc/apm),(etc/apm/suspend.d)} 53 | etc/apparmor | {(etc),(etc/apparmor)} 67 | etc/apparmor/init | {(etc),(etc/apparmor),(etc/apparmor/init)} 68 | etc/apparmor/init/network-interface-security | {(etc),(etc/apparmor),(etc/apparmor/init),(etc/apparmor/init/network-interface-security)} (15 rows)
So, I can see now, that in this sort – etc/apparmor/X is actually before /etc/apparmor.d/X. Which kinda makes sense. Let's compare the two orders on their own:
Old approach:
$ WITH RECURSIVE c AS ( SELECT id, dirname AS path FROM dirs WHERE id in (53, 54) UNION ALL SELECT dirs.id, c.path || '/' || dirs.dirname AS path FROM dirs JOIN c ON dirs.parent_id = c.id ) SELECT id, path FROM c ORDER BY path; id | path ----+------------------------------------------- 53 | apparmor 54 | apparmor.d 55 | apparmor.d/abstractions 56 | apparmor.d/abstractions/apparmor_api 57 | apparmor.d/abstractions/ubuntu-browsers.d 58 | apparmor.d/disable 59 | apparmor.d/force-complain 60 | apparmor.d/libvirt 61 | apparmor.d/local 62 | apparmor.d/local/abstractions 63 | apparmor.d/tunables 64 | apparmor.d/tunables/home.d 65 | apparmor.d/tunables/multiarch.d 66 | apparmor.d/tunables/xdg-user-dirs.d 67 | apparmor/init 68 | apparmor/init/network-interface-security (16 rows)
and the new one:
$ WITH RECURSIVE c AS ( SELECT id, dirname AS path FROM dirs WHERE id in (53, 54) UNION ALL SELECT dirs.id, c.path || '/' || dirs.dirname AS path FROM dirs JOIN c ON dirs.parent_id = c.id ) SEARCH DEPTH FIRST BY path SET ordercol select id, path from c order by ordercol; id | path ----+------------------------------------------- 53 | apparmor 67 | apparmor/init 68 | apparmor/init/network-interface-security 54 | apparmor.d 55 | apparmor.d/abstractions 56 | apparmor.d/abstractions/apparmor_api 57 | apparmor.d/abstractions/ubuntu-browsers.d 58 | apparmor.d/disable 59 | apparmor.d/force-complain 60 | apparmor.d/libvirt 61 | apparmor.d/local 62 | apparmor.d/local/abstractions 63 | apparmor.d/tunables 64 | apparmor.d/tunables/home.d 65 | apparmor.d/tunables/multiarch.d 66 | apparmor.d/tunables/xdg-user-dirs.d (16 rows)
Please note that apparmor/init and apparmor/init/network-interface-security are in much better place now – immediately after apparmor/, and not apparmor.d. Nice!
What's cool, we can also now also have order by breadth first:
$ WITH RECURSIVE c AS ( SELECT id, dirname AS path FROM dirs WHERE parent_id is null UNION ALL SELECT dirs.id, c.path || '/' || dirs.dirname AS path FROM dirs JOIN c ON dirs.parent_id = c.id ) SEARCH BREADTH FIRST BY id SET ordercol SELECT id, path FROM c ORDER BY ordercol limit 15; id | path ----+--------------------- 1 | etc 2 | etc/.java 3 | etc/GNUstep 4 | etc/ImageMagick-6 5 | etc/Muttrc.d 6 | etc/NetworkManager 15 | etc/ODBCDataSources 16 | etc/OpenCL 18 | etc/PackageKit 19 | etc/UPower 20 | etc/X11 42 | etc/acpi 44 | etc/alsa 46 | etc/alternatives 47 | etc/apache2 (15 rows)
yeah – There are many dirs in /etc, so to see some dirs deeper I will have to offset quite a lot:
$ WITH RECURSIVE c AS ( SELECT id, dirname AS path FROM dirs WHERE parent_id is null UNION ALL SELECT dirs.id, c.path || '/' || dirs.dirname AS path FROM dirs JOIN c ON dirs.parent_id = c.id ) SEARCH BREADTH FIRST BY id SET ordercol SELECT id, path FROM c ORDER BY ordercol limit 15 offset 170; id | path -----+--------------------------------------- 420 | etc/vulkan 424 | etc/wpa_supplicant 425 | etc/xdg 433 | etc/xml 7 | etc/NetworkManager/conf.d 8 | etc/NetworkManager/dispatcher.d 12 | etc/NetworkManager/dnsmasq.d 13 | etc/NetworkManager/dnsmasq-shared.d 14 | etc/NetworkManager/system-connections 17 | etc/OpenCL/vendors 21 | etc/X11/Xreset.d 22 | etc/X11/Xresources 23 | etc/X11/Xsession.d 24 | etc/X11/app-defaults 25 | etc/X11/cursors (15 rows)
This is awesome.
For the second part of the change – cycles, I will need different dataset.
So I took a small bit of Ticket to Ride map:
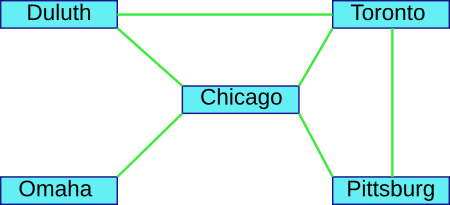
and converted it to table:
$ create table conns ( c_from text, c_to text, primary key (c_from, c_to) ); CREATE TABLE $ insert into conns (c_from, c_to) values ( 'Chicago', 'Duluth' ), ( 'Duluth', 'Chicago' ), ( 'Chicago', 'Toronto' ), ( 'Toronto', 'Chicago' ), ( 'Chicago', 'Pittsburg' ), ( 'Pittsburg', 'Chicago' ), ( 'Pittsburg', 'Toronto' ), ( 'Toronto', 'Pittsburg' ), ( 'Duluth', 'Toronto' ), ( 'Toronto', 'Duluth' ), ( 'Chicago', 'Omaha' ), ( 'Omaha', 'Chicago' ); INSERT 0 12
Now, let's print all possible routes we can go through, starting from Chicago. Simplistic approach:
$ WITH RECURSIVE c AS ( SELECT c_from, c_to, array[ c_from, c_to ] as track from conns where c_from = 'Chicago' UNION ALL SELECT n.c_from, n.c_to, c.track || n.c_to FROM conns n join c on n.c_from = c.c_to ) SELECT * FROM c;
will, of course, never end, because there are cycles in here.
But now, we can have cycle detection! So let's try it:
$ WITH RECURSIVE c AS ( SELECT NULL as c_from, 'Chicago' as c_to, ARRAY[ 'Chicago' ] as track UNION ALL SELECT n.c_from, n.c_to, c.track || n.c_to FROM conns n join c on n.c_from = c.c_to ) CYCLE c_to SET is_cycle to true default false using cycle_path SELECT * FROM c; c_from | c_to | track | is_cycle | cycle_path -----------+-----------+--------------------------------------------+----------+------------------------------------------------------ | Chicago | {Chicago} | f | {(Chicago)} Chicago | Duluth | {Chicago,Duluth} | f | {(Chicago),(Duluth)} Chicago | Toronto | {Chicago,Toronto} | f | {(Chicago),(Toronto)} Chicago | Pittsburg | {Chicago,Pittsburg} | f | {(Chicago),(Pittsburg)} Chicago | Omaha | {Chicago,Omaha} | f | {(Chicago),(Omaha)} Duluth | Chicago | {Chicago,Duluth,Chicago} | t | {(Chicago),(Duluth),(Chicago)} Toronto | Chicago | {Chicago,Toronto,Chicago} | t | {(Chicago),(Toronto),(Chicago)} Pittsburg | Chicago | {Chicago,Pittsburg,Chicago} | t | {(Chicago),(Pittsburg),(Chicago)} Pittsburg | Toronto | {Chicago,Pittsburg,Toronto} | f | {(Chicago),(Pittsburg),(Toronto)} Toronto | Pittsburg | {Chicago,Toronto,Pittsburg} | f | {(Chicago),(Toronto),(Pittsburg)} Duluth | Toronto | {Chicago,Duluth,Toronto} | f | {(Chicago),(Duluth),(Toronto)} Toronto | Duluth | {Chicago,Toronto,Duluth} | f | {(Chicago),(Toronto),(Duluth)} Omaha | Chicago | {Chicago,Omaha,Chicago} | t | {(Chicago),(Omaha),(Chicago)} Duluth | Chicago | {Chicago,Toronto,Duluth,Chicago} | t | {(Chicago),(Toronto),(Duluth),(Chicago)} Toronto | Chicago | {Chicago,Duluth,Toronto,Chicago} | t | {(Chicago),(Duluth),(Toronto),(Chicago)} Toronto | Chicago | {Chicago,Pittsburg,Toronto,Chicago} | t | {(Chicago),(Pittsburg),(Toronto),(Chicago)} Pittsburg | Chicago | {Chicago,Toronto,Pittsburg,Chicago} | t | {(Chicago),(Toronto),(Pittsburg),(Chicago)} Pittsburg | Toronto | {Chicago,Toronto,Pittsburg,Toronto} | t | {(Chicago),(Toronto),(Pittsburg),(Toronto)} Toronto | Pittsburg | {Chicago,Duluth,Toronto,Pittsburg} | f | {(Chicago),(Duluth),(Toronto),(Pittsburg)} Toronto | Pittsburg | {Chicago,Pittsburg,Toronto,Pittsburg} | t | {(Chicago),(Pittsburg),(Toronto),(Pittsburg)} Duluth | Toronto | {Chicago,Toronto,Duluth,Toronto} | t | {(Chicago),(Toronto),(Duluth),(Toronto)} Toronto | Duluth | {Chicago,Duluth,Toronto,Duluth} | t | {(Chicago),(Duluth),(Toronto),(Duluth)} Toronto | Duluth | {Chicago,Pittsburg,Toronto,Duluth} | f | {(Chicago),(Pittsburg),(Toronto),(Duluth)} Duluth | Chicago | {Chicago,Pittsburg,Toronto,Duluth,Chicago} | t | {(Chicago),(Pittsburg),(Toronto),(Duluth),(Chicago)} Pittsburg | Chicago | {Chicago,Duluth,Toronto,Pittsburg,Chicago} | t | {(Chicago),(Duluth),(Toronto),(Pittsburg),(Chicago)} Pittsburg | Toronto | {Chicago,Duluth,Toronto,Pittsburg,Toronto} | t | {(Chicago),(Duluth),(Toronto),(Pittsburg),(Toronto)} Duluth | Toronto | {Chicago,Pittsburg,Toronto,Duluth,Toronto} | t | {(Chicago),(Pittsburg),(Toronto),(Duluth),(Toronto)} (27 rows)
This is as really cool. What's more – I didn't even had to add any condition on the is_cycle, it was sufficient that it's calculated, and processing stopped. And I can still add “WHERE is_cycle = false" to weed out the connections that cycle back to city that was already visited:
$ WITH RECURSIVE c AS ( SELECT NULL as c_from, 'Chicago' as c_to, ARRAY[ 'Chicago' ] as track UNION ALL SELECT n.c_from, n.c_to, c.track || n.c_to FROM conns n join c on n.c_from = c.c_to ) CYCLE c_to SET is_cycle to true default false using cycle_path select * from c where is_cycle = false; c_from | c_to | track | is_cycle | cycle_path -----------+-----------+------------------------------------+----------+-------------------------------------------- | Chicago | {Chicago} | f | {(Chicago)} Chicago | Duluth | {Chicago,Duluth} | f | {(Chicago),(Duluth)} Chicago | Toronto | {Chicago,Toronto} | f | {(Chicago),(Toronto)} Chicago | Pittsburg | {Chicago,Pittsburg} | f | {(Chicago),(Pittsburg)} Chicago | Omaha | {Chicago,Omaha} | f | {(Chicago),(Omaha)} Pittsburg | Toronto | {Chicago,Pittsburg,Toronto} | f | {(Chicago),(Pittsburg),(Toronto)} Toronto | Pittsburg | {Chicago,Toronto,Pittsburg} | f | {(Chicago),(Toronto),(Pittsburg)} Duluth | Toronto | {Chicago,Duluth,Toronto} | f | {(Chicago),(Duluth),(Toronto)} Toronto | Duluth | {Chicago,Toronto,Duluth} | f | {(Chicago),(Toronto),(Duluth)} Toronto | Pittsburg | {Chicago,Duluth,Toronto,Pittsburg} | f | {(Chicago),(Duluth),(Toronto),(Pittsburg)} Toronto | Duluth | {Chicago,Pittsburg,Toronto,Duluth} | f | {(Chicago),(Pittsburg),(Toronto),(Duluth)} (11 rows)
All in all – both these things look amazing, and will greatly help writing queries for hierarchical data.
Huge thanks to all involved 🙂
Pittsburgh is spelled with an “h” at the end
Awesome feat., what would be the impact on the cache-ability of such queries?