some time ago i wrote a piece on values(),() in postgresql 8.2, saying that multi-row inserts are very fast.
some people said that my benchmark is pretty useless as i didn't take into consideration transactions.
others asked me to translate the text to english.
so i decided to redo the test, with more test scenarios, and write it up in english. this is the summary.
at first what i used, what i tested and how.
i used a linux machine, with these things inside:
- cpu: AMD Sempron(tm) Processor 2600+ (1.6ghz)
- memory: 3gb
- discs: 4 250gb hitachi sata discs (only one was used)
i tried to make the machine as predictable as possible, thus i stopped all daemons which were not neccessary. full ps auxwwf output is provided in results tar file. basically – there is postgresql, sshd, openvpn, dhclient and some gettys. no cron, atd, smtpd, httpd or anything like this.
then i wrote a small program which generated test files. i do not distribute test files themselves, as in total they use nearly 70gb!
then i wrote another small program – which basically ran all of the tests (3 times to get an average).
full set of results is downloadable as tar file, which contains 10598 files (tar file is 350k, unpacked directory takes 42megs).
one very important notice. all tests that i have performed inserted random data to table of this structure:
- id int4 primary key,
- some_text text,
- bool_1 bool,
- bool_2 bool,
- some_date date,
- some_timestamp timestamp
so results (especially “break-points" where there is no further gain) will be different when inserting to another tables. the only point of this benchmark is to show which approach can give which results. and what's really worth the trouble 🙂
to have some perspective, i did test of fastest way that is available in standard postgresql – copy, and the slowest one – a lot of single-row inserts, without transactions, without preparing.
copy'ing the data took:
- 17.02 second
- 1451 cpu in user mode
- 191 cpu in system mode
- 20.67 cpu in iowait
(cpu units are “USER_HZ" as described in filesystems/proc.txt.gz file in linux kernel documentation).
simple inserts took:
- 622.66 seconds
- 43208 cpu in user mode
- 14175 cpu in system mode
- 64.33 cpu in iowait
whoat. that's quite a difference 🙂 copy time is about 2% of inserts time. i wonder how close to these 2% we can get with different inserts.
so, let's see how things will be better if i would use transactions.
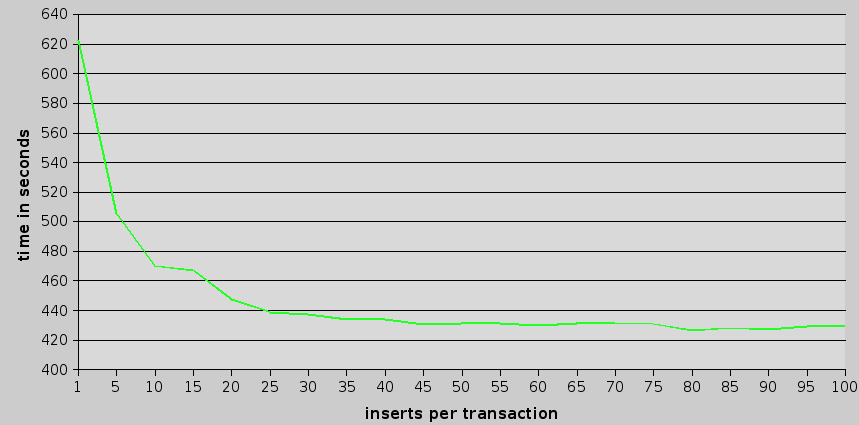
as we can see, using transactions speeds things up to around 425-430 seconds. this gives about 32% boost. how about cpu usage?
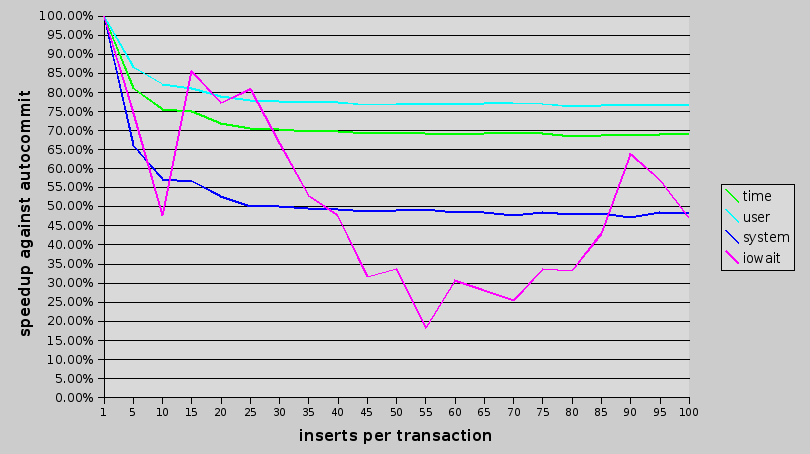
from the graph i can deduce that iowaits are somehow random, so i will not show them in next charts (after all, all that i'm really interested in total time).
biggest gain is showed in system cpu usage. reasons? i have some theories, but none is bases on hard facts 🙂
anyway – it seems that the serious gains are given by putting 25 inserts in transaction. above this – there still some gains, but not really noticeable.
ok, so now let's check if prepare'ing the insert statements will bring any good.
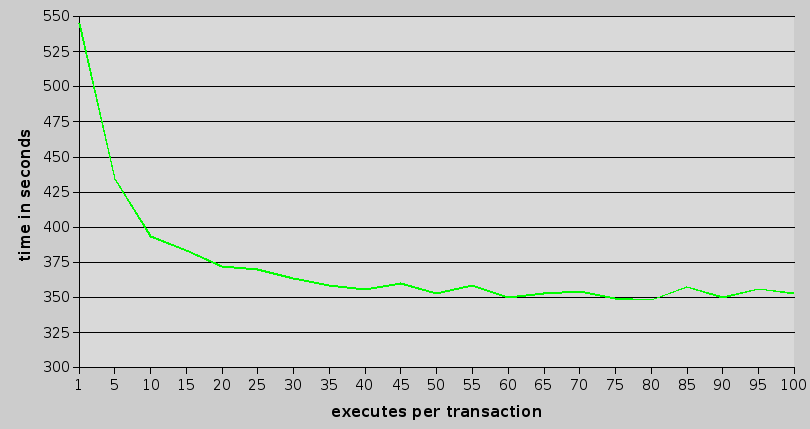
it's definitely faster. let's look at the speedups:
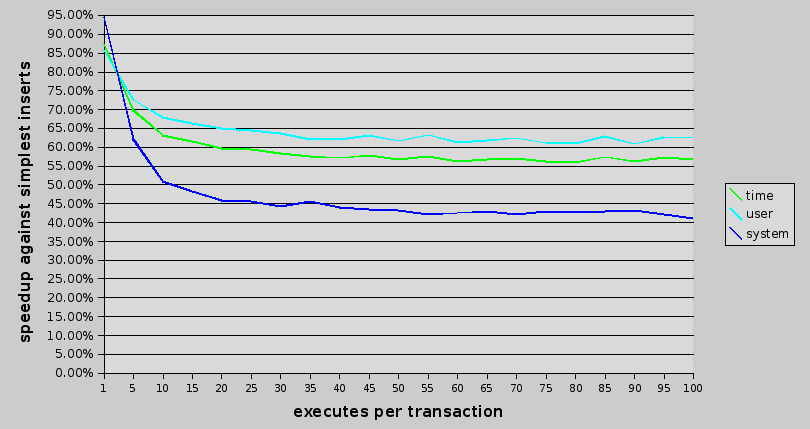
(percentage is against simplest inserts, no prepare, no transactions).
as it can be seen, adding prepare shaves some time and some cpu usage, so it's clearly good idea. using prepare and inserts we can get the time down to about 60% of original. which isn't too bad.
the last thing that can be done is making the inserts insert more rows in one call.
since we know that prepare'ing is good, i will show results only for prepared statements.
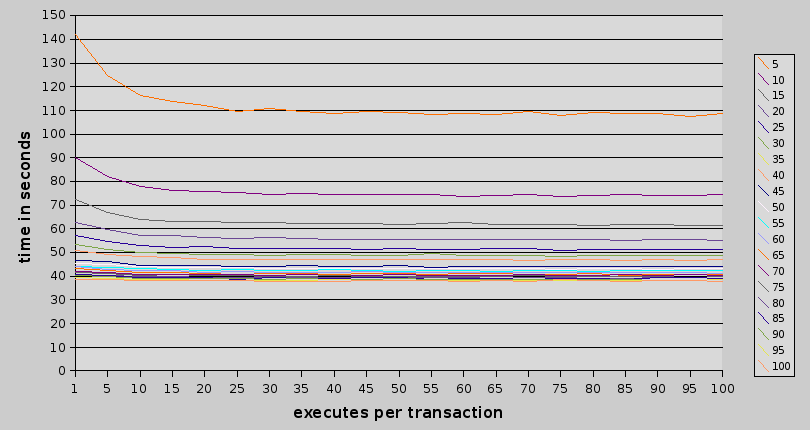
different lines show different number of rows inserted by single statement.
this image shows (i hope it does) that (just like with simple inserts) transaction bonus lasts only for some time – at most 25 statements per transaction.
and what about the point when there is no further benefit from adding additional rows to a single statement?
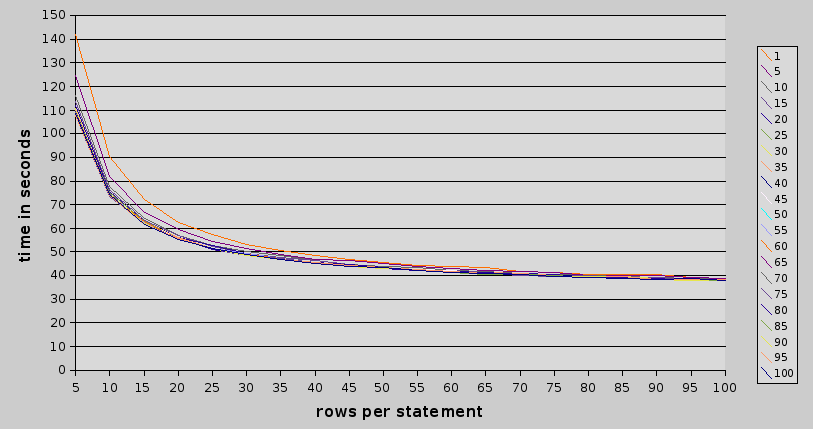
different lines show different number of statement per transaction.
with multi-rows per insert there is no clear “end of speedup". at least not in this test.
so, let's have a summary.
- copy did the job in 17.02 seconds
- simplest possible inserts did it in 622.66 seconds
- best-possible way of grouping inserts in transactions was 80 inserts per transactions, and it used 426.81 seconds
- prepared inserts in autocommit mode did the job in 545.23 seconds
- best-possible way of grouping prepared inserts in transactions – also 80 inserts per transaction, used 348.38 seconds.
- simplest multi-row inserts (5 rows per insert, no prepared statement, autocommit) did the job in 164 seconds
- best possible way of inserting with multiple rows was using 100 rows per statement, 100 statements per transaction, using prepared statements – it did it's work in 37.73 seconds.
- best possible multi-row insert without transactions or prepared statements – 100 rows per statement. time used – 42.07 second!
so, if you want to insert data as fast as possible – use copy (or better yet – pgbulkload). if for whatever reason you can't use copy, then use multi-row inserts (new in 8.2!). then if you can, bundle them in transactions, and use prepared transactions, but generally – they don't give you much.
all other data – please take a look at a spreadsheet (openoffice format, 42k size) with results.
This is really very interesting. Even more interesting is your comment about checking out pgbulkload. Will there be any chance that you will look into that performance based on your current dataset?
In addition to that, just wondering if the copy would be slowed down considerably by having a large index or PK or Fk etc?
@lotso:
maybe i’ll do more tests in some time (depending on free time).
on the other hand – you can try it yourself – all programs used by me are downloadable, so you get get them, modify to test what you need, and then run the test on your machine.
ads asked me to provide a bit more info.
import consisted of 1 million rows.
all fields of all rows were filled.
some_text field was filled with alphanumerics, random string, with length from 5 to 20 characters (uniform distribution).
it makes average row contain:
– id: 4 bytes
– some_text: average 16 bytes
– bool_1: 1 byte
– bool_2: 1 byte
– some_date: 4 bytes
– some_timestamp: 8 bytes
plus some postgresql internal fields.
I’ve only just recently found this article and implemented the techniques described in it. I have to say that I’m absolutely amazed at the speed increase that has been achieved. Fantastic work, thanks!
Despite the age of this article (2012-2007=5 years), it has been certified by David Fetter as being “Still Valid ™”. Date of next inspection: 2017-09-25
# JOEL JACOBSON – Joel its 2017 and time to inspect again …