On 19th of July, Simon Riggs committed patch:
Cascading replication feature FOR streaming log-based replication. Standby servers can now have WALSender processes, which can WORK WITH either WALReceiver OR archive_commands TO pass DATA. Fully updated docs, including NEW conceptual terms OF sending server, upstream AND downstream servers. WALSenders TERMINATED WHEN promote TO master. Fujii Masao, review, rework AND doc rewrite BY Simon Riggs
Streaming replication is relatively new, added in 9.0. Since beginning it shared the same limitation that normal WAL-files based replication has, that is – there is only one source of data. That is master.
While it makes sense, it is also pretty cool to be able to make slave source of replication for some other systems. For example – not to keep master occupied with such tasks.
Now, with the patch, we can setup replication schema like this:
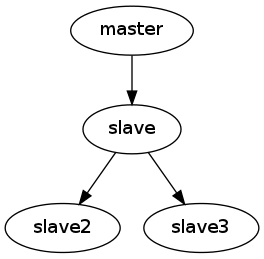
So, let's test it.
To make it work I will need some master database and 3 slaves, made off the master. Seems simple enough.
=$ mkdir master =$ initdb -D master ... =$ vim master/postgresql.conf
In the postgresql.conf, I change:
- port = 4001
- wal_level = hot_standby
- checkpoint_segments = 20
- archive_mode = on
- archive_command = ‘/bin/true'
- max_wal_senders = 3
- wal_keep_segments = 100
- logging_collector = on
- log_checkpoints = on
- log_connections = on
- log_line_prefix = ‘%m %r %u %d %p: ‘
I also set pg_hba.conf to something that matches my test environment:
# TYPE DATABASE USER ADDRESS METHOD local replication all trust local all all trust host all all 127.0.0.1/32 trust
With master prepared that way, I can start it:
=$ pg_ctl -D master start server starting =$ head -n 1 master/postmaster.pid | xargs -IPG ps uwf -p PG --ppid PG USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND depesz 9332 0.0 0.0 66456 7496 pts/3 S 12:11 0:00 /home/pgdba/work/bin/postgres -D master depesz 9333 0.0 0.0 26140 724 ? Ss 12:11 0:00 \_ postgres: logger process depesz 9335 0.0 0.0 66456 1276 ? Ss 12:11 0:00 \_ postgres: writer process depesz 9336 0.0 0.0 66456 1012 ? Ss 12:11 0:00 \_ postgres: wal writer process depesz 9337 0.0 0.0 67164 2040 ? Ss 12:11 0:00 \_ postgres: autovacuum launcher process depesz 9338 0.0 0.0 26136 732 ? Ss 12:11 0:00 \_ postgres: archiver process depesz 9339 0.0 0.0 26136 932 ? Ss 12:11 0:00 \_ postgres: stats collector process =$ psql -p 4001 -d postgres -c "select version()" version ------------------------------------------------------------------------------------------------------------------------ PostgreSQL 9.2devel on x86_64-unknown-linux-gnu, compiled by gcc-4.5.real (Ubuntu/Linaro 4.5.2-8ubuntu4) 4.5.2, 64-bit (1 row)
All looks ok.
One note – you might not understand why I used /bin/true as archive_command. Reason is very simple – archive has to be set to something, otherwise archive_mode cannot be enabled, and this will cause problems with backups, but on the other hand – I will not need to use the wal archive, since I have pretty large wal_keep_segments.
Now, we'll setup the slaves. Starting with the first one of course:
=$ psql -p 4001 -d postgres -c "select pg_start_backup('whatever')" pg_start_backup ----------------- 0/2000020 (1 row) =$ rsync -a master/ slave/ =$ psql -p 4001 -d postgres -c "select pg_stop_backup()" NOTICE: pg_stop_backup complete, all required WAL segments have been archived pg_stop_backup ---------------- 0/20000D8 (1 row)
Of course we need some tidying of the slave:
=$ rm -f slave/pg_xlog/???????????????????????? slave/pg_xlog/archive_status/* slave/pg_log/* slave/postmaster.pid =$ vim slave/postgresql.conf
In the config, I change:
- port = 4002
- hot_standby = on
And I also create recovery.conf in slave/, with this content:
restore_command = '/bin/false' standby_mode = 'on' primary_conninfo = 'port=4001 user=depesz' trigger_file = '/tmp/slave.finish.recovery'
And with this in place I can start slave:
=$ pg_ctl -D slave start server starting =$ head -n 1 slave/postmaster.pid | xargs -IPG ps uwf -p PG --ppid PG USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND depesz 13082 1.5 0.0 66484 7492 pts/3 S 12:51 0:00 /home/pgdba/work/bin/postgres -D slave depesz 13083 0.0 0.0 26136 716 ? Ss 12:51 0:00 \_ postgres: logger process depesz 13084 0.0 0.0 66556 1428 ? Ss 12:51 0:00 \_ postgres: startup process recovering 000000010000000000000006 depesz 13087 2.7 0.0 81504 3064 ? Ss 12:51 0:00 \_ postgres: wal receiver process streaming 0/6000078 depesz 13091 0.0 0.0 66484 1012 ? Ss 12:51 0:00 \_ postgres: writer process depesz 13092 0.0 0.0 26132 896 ? Ss 12:51 0:00 \_ postgres: stats collector process =$ head -n 1 master/postmaster.pid | xargs -IPG ps uwf -p PG --ppid PG USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND depesz 12981 0.2 0.0 66456 7520 pts/3 S 12:50 0:00 /home/pgdba/work/bin/postgres -D master depesz 12982 0.0 0.0 26140 724 ? Ss 12:50 0:00 \_ postgres: logger process depesz 12984 0.0 0.0 66456 1016 ? Ss 12:50 0:00 \_ postgres: writer process depesz 12985 0.0 0.0 66456 1012 ? Ss 12:50 0:00 \_ postgres: wal writer process depesz 12986 0.0 0.0 67296 2096 ? Ss 12:50 0:00 \_ postgres: autovacuum launcher process depesz 12987 0.0 0.0 26136 732 ? Ss 12:50 0:00 \_ postgres: archiver process depesz 12988 0.0 0.0 26136 1040 ? Ss 12:50 0:00 \_ postgres: stats collector process depesz 13088 0.3 0.0 67428 2480 ? Ss 12:51 0:00 \_ postgres: wal sender process depesz [local] streaming 0/6000078
One note – I used “user=depesz" in primary_conninfo, because I run the tests on depesz system account, and initdb made superuser named depesz, and not postgres.
So, we now have replication master -> slave setup, so we can test it:
=$ psql -p 4001 -d postgres -c "create table i (x int4)"; psql -p 4002 -d postgres -c '\d i' CREATE TABLE TABLE "public.i" COLUMN | TYPE | Modifiers --------+---------+----------- x | INTEGER |
All looks OK. Now, we can add slave2 and slave3. Since I'm lazy, I will just stop slave, copy slave to slave2/slave3 and then modify them:
=$ pg_ctl -D slave stop waiting for server to shut down.... done server stopped =$ rsync -a slave/ slave2/ =$ rsync -a slave/ slave3/ =$ pg_ctl -D slave start server starting
Slave2 and 3 will be basically the same as slave, but with different port, and connecting to 4002 (slave) instead of 4001 (master) for their WAL. So, let's do the changes:
=$ perl -pi -e 's/port = 4002/port = 4003/' slave2/postgresql.conf =$ perl -pi -e 's/port = 4002/port = 4004/' slave3/postgresql.conf =$ perl -pi -e 's/port=4001/port=4002/' slave{2,3}/recovery.conf =$ perl -pi -e 's/slave.finish.recovery/slave2.finish.recovery/' slave2/recovery.conf =$ perl -pi -e 's/slave.finish.recovery/slave3.finish.recovery/' slave3/recovery.conf
Now we have:
=$ ack "^port" */postgresql.conf master/postgresql.conf 63:port = 4001 # (change requires restart) slave2/postgresql.conf 63:port = 4003 # (change requires restart) slave3/postgresql.conf 63:port = 4004 # (change requires restart) slave/postgresql.conf 63:port = 4002 # (change requires restart) =$ ack port */recovery.conf slave2/recovery.conf 3:primary_conninfo = 'port=4002 user=depesz' slave3/recovery.conf 3:primary_conninfo = 'port=4002 user=depesz' slave/recovery.conf 3:primary_conninfo = 'port=4001 user=depesz'
So, let's start them:
=$ for a in slave2 slave3; do pg_ctl -D $a/ start; done server starting server starting
And now we see the processes:
=$ head -n 1 -q */*.pid | xargs -IPG echo "-p PG --ppid PG" | xargs ps uwf USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND depesz 14031 0.0 0.0 66488 7496 pts/3 S 13:03 0:00 /home/pgdba/work/bin/postgres -D slave3 depesz 14032 0.0 0.0 26140 720 ? Ss 13:03 0:00 \_ postgres: logger process depesz 14033 0.0 0.0 66556 1400 ? Ss 13:03 0:00 \_ postgres: startup process recovering 000000010000000000000006 depesz 14063 0.0 0.0 79456 2148 ? Ss 13:03 0:00 \_ postgres: wal receiver process streaming 0/6012ED0 depesz 14069 0.0 0.0 66488 1532 ? Ss 13:03 0:00 \_ postgres: writer process depesz 14070 0.0 0.0 26136 900 ? Ss 13:03 0:00 \_ postgres: stats collector process depesz 14026 0.0 0.0 66492 7496 pts/3 S 13:03 0:00 /home/pgdba/work/bin/postgres -D slave2 depesz 14042 0.0 0.0 26144 720 ? Ss 13:03 0:00 \_ postgres: logger process depesz 14043 0.0 0.0 66560 1400 ? Ss 13:03 0:00 \_ postgres: startup process recovering 000000010000000000000006 depesz 14067 0.0 0.0 79460 2148 ? Ss 13:03 0:00 \_ postgres: wal receiver process streaming 0/6012ED0 depesz 14071 0.0 0.0 66492 1532 ? Ss 13:03 0:00 \_ postgres: writer process depesz 14072 0.0 0.0 26140 900 ? Ss 13:03 0:00 \_ postgres: stats collector process depesz 14021 0.0 0.0 66488 7528 pts/3 S 13:03 0:00 /home/pgdba/work/bin/postgres -D slave depesz 14037 0.0 0.0 26140 724 ? Ss 13:03 0:00 \_ postgres: logger process depesz 14038 0.0 0.0 66560 1572 ? Ss 13:03 0:00 \_ postgres: startup process recovering 000000010000000000000006 depesz 14048 0.0 0.0 66488 1536 ? Ss 13:03 0:00 \_ postgres: writer process depesz 14050 0.0 0.0 26136 904 ? Ss 13:03 0:00 \_ postgres: stats collector process depesz 14052 0.0 0.0 79460 2136 ? Ss 13:03 0:00 \_ postgres: wal receiver process streaming 0/6012ED0 depesz 14064 0.0 0.0 67332 2476 ? Ss 13:03 0:00 \_ postgres: wal sender process depesz [local] streaming 0/6012ED0 depesz 14068 0.0 0.0 67452 2476 ? Ss 13:03 0:00 \_ postgres: wal sender process depesz [local] streaming 0/6012ED0 depesz 12981 0.0 0.0 66456 7524 pts/3 S 12:50 0:00 /home/pgdba/work/bin/postgres -D master depesz 12982 0.0 0.0 26140 724 ? Ss 12:50 0:00 \_ postgres: logger process depesz 12984 0.0 0.0 66456 1780 ? Ss 12:50 0:00 \_ postgres: writer process depesz 12985 0.0 0.0 66456 1012 ? Ss 12:50 0:00 \_ postgres: wal writer process depesz 12986 0.0 0.0 67296 2156 ? Ss 12:50 0:00 \_ postgres: autovacuum launcher process depesz 12987 0.0 0.0 26136 732 ? Ss 12:50 0:00 \_ postgres: archiver process depesz 12988 0.0 0.0 26136 1040 ? Ss 12:50 0:00 \_ postgres: stats collector process depesz 14053 0.0 0.0 67444 2520 ? Ss 13:03 0:00 \_ postgres: wal sender process depesz [local] streaming 0/6012ED0
Please note that master Pg has only one sender process (pid 14053), slave Pg has receiver (14052) and two senders (14064 and 14068), and slave2 and slave3 have only single receiver (14067 and 14063).
So, now we should test if it all works well, so:
=$ psql -d postgres -p 4001 -c 'insert into i(x) values (123)' for port in 4002 4003 4004 do echo "port=$port" psql -p $port -d postgres -c "select * from i" done INSERT 0 1 port=4002 x --- (0 rows) port=4003 x --- (0 rows) port=4004 x --- (0 rows)
The tables are empty. They should have some data, but it might be simply because of replication lag. So let's retry the check, without insert now:
=$ for port in 4002 4003 4004 do echo "port=$port" psql -p $port -d postgres -c "select * from i" done port=4002 x ----- 123 (1 row) port=4003 x ----- 123 (1 row) port=4004 x ----- 123 (1 row)
And all works fine now. Great.
The only missing feature is ability to make slaves-off-slave still work when slave gets promoted to standalone, but unfortunately, it's not here:
=$ touch /tmp/slave.finish.recovery; sleep 5; head -n 1 -q */*.pid | xargs -IPG echo "-p PG --ppid PG" | xargs ps uwf USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND depesz 14896 0.1 0.0 66488 7524 pts/3 S 13:18 0:00 /home/pgdba/work/bin/postgres -D slave3 depesz 14897 0.0 0.0 26140 720 ? Ss 13:18 0:00 \_ postgres: logger process depesz 14898 0.0 0.0 66556 1696 ? Ss 13:18 0:00 \_ postgres: startup process waiting for 000000010000000000000006 depesz 14901 0.0 0.0 66488 1276 ? Ss 13:18 0:00 \_ postgres: writer process depesz 14902 0.0 0.0 26136 900 ? Ss 13:18 0:00 \_ postgres: stats collector process depesz 14883 0.1 0.0 66492 7528 pts/3 S 13:18 0:00 /home/pgdba/work/bin/postgres -D slave2 depesz 14885 0.0 0.0 26144 724 ? Ss 13:18 0:00 \_ postgres: logger process depesz 14886 0.0 0.0 66560 1700 ? Ss 13:18 0:00 \_ postgres: startup process waiting for 000000010000000000000006 depesz 14890 0.0 0.0 66492 1280 ? Ss 13:18 0:00 \_ postgres: writer process depesz 14891 0.0 0.0 26140 904 ? Ss 13:18 0:00 \_ postgres: stats collector process depesz 14021 0.0 0.0 66488 7528 pts/3 S 13:03 0:00 /home/pgdba/work/bin/postgres -D slave depesz 14037 0.0 0.0 26140 724 ? Ss 13:03 0:00 \_ postgres: logger process depesz 14048 0.0 0.0 66488 1780 ? Ss 13:03 0:00 \_ postgres: writer process depesz 14050 0.0 0.0 26136 1032 ? Ss 13:03 0:00 \_ postgres: stats collector process depesz 15018 0.0 0.0 66488 1016 ? Ss 13:20 0:00 \_ postgres: wal writer process depesz 15019 0.0 0.0 67320 2100 ? Ss 13:20 0:00 \_ postgres: autovacuum launcher process depesz 15020 0.0 0.0 26136 912 ? Ss 13:20 0:00 \_ postgres: archiver process last was 00000002.history depesz 12981 0.0 0.0 66456 7524 pts/3 S 12:50 0:00 /home/pgdba/work/bin/postgres -D master depesz 12982 0.0 0.0 26140 724 ? Ss 12:50 0:00 \_ postgres: logger process depesz 12984 0.0 0.0 66456 1780 ? Ss 12:50 0:00 \_ postgres: writer process depesz 12985 0.0 0.0 66456 1012 ? Ss 12:50 0:00 \_ postgres: wal writer process depesz 12986 0.0 0.0 67296 2164 ? Ss 12:50 0:00 \_ postgres: autovacuum launcher process depesz 12987 0.0 0.0 26136 732 ? Ss 12:50 0:00 \_ postgres: archiver process depesz 12988 0.0 0.0 26136 1040 ? Ss 12:50 0:00 \_ postgres: stats collector process
As you can see the sender in slave got killed, and thus slave2 and slave3 are still slaves, but without source of WAL.
Logs of slave2 and slave3 PostgreSQL show clear reason why it doesn't work:
2011-07-26 13:26:41.483 CEST 16318: FATAL: timeline 2 of the primary does not match recovery target timeline 1
Clearly – slave is using timeline == 2, while slave2 and slave3 are still on timeline == 1.
Theoretically it should be simple to fix, since slave has pg_xlog/00000002.history file, but the functionality to switch timelines in recovery is simply not there yet.
Anyway – ability to have slaves that are receiving WAL from other slaves, is pretty cool, and definitely a welcome addition.
Hey,
I did discuss the “swithing timeline” issue with Masao-san during last pgcon. I’m not sure, but I think you just cannot switch timeline using streaming replication, but you can do it from archives.
Maybe you can setup log shipping from slave1 to slave2 and 3, and add in the recovery.conf:
recovery_target_timeline = ‘latest’
Then restart slave2 and 3 after the slave1 promotion.
Hi there!
I’m trying to get a pg_basebackup from a new SLAVE server running PostgreSQL 9.2.
But I’ve got the following error: 2016-01-09 01:13:39.183 UTC|774|FATAL: timeline 2 of the primary does not match recovery target timeline 4
Please, also check here: http://dba.stackexchange.com/questions/125709/recovery-from-live-to-a-new-slave-server-postgresql-error#comment231865_125709
Is there anything you could help me with?
I’ve been working on it for 20h and couldn’t solve! =\
Thank you!